How to Build a Data Closed-loop Platform for Autonomous Driving?
0 Introduction
Recently autonomous driving is linked with the concept of data closed loop, because it is widely acknowledged that development engineering of autonomous driving is to solve a “long-tail problem” of rare events, where corner cases occurring from time to time, bring valuable sources for data-driven algorithms & models.

What kind of techiques and modules in such a data closed loop platform to employ? First, we assure the algorithms and models are data driven; Second, the fruitable data needs a smart way to be mined for use.
Let’s see some examples:
- Tesla’s data engine:

2. Google Waymo’s ML factory:

3. Nvidia’s AV ML platform MAGLEV:

It is seen the components in the data closed loop of autonomous driving are:
*Data driven models for autonomous driving;
*Cloud computing infrastructure and big data processing;
*Annotation tools for training data;
*Large scale model training platform;
*Model testing and verification;
*Related machine learning techniques.
1 Data driven models for autonomous driving
Usually the self driving platform is classified as end-to-end (E2E) or modular system, shown as below:

Usually it is obvious that the E2E system applies data driven models, for example:
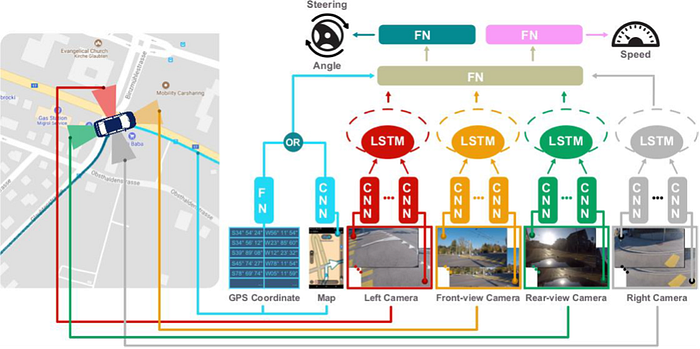
For a modular system pipeline, it is observed that more data driven models are designed for each module:
- Perception: 2D/3D detection, segmetation, tracking and (early/late) fusion etc.
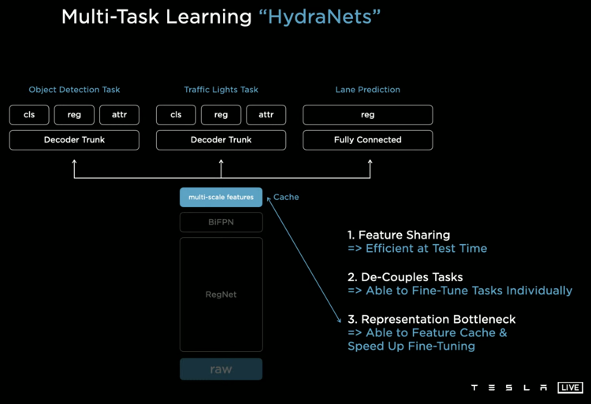

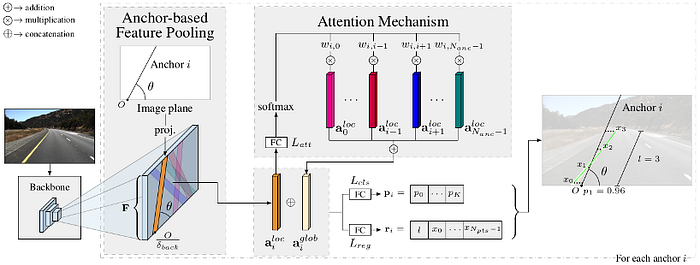
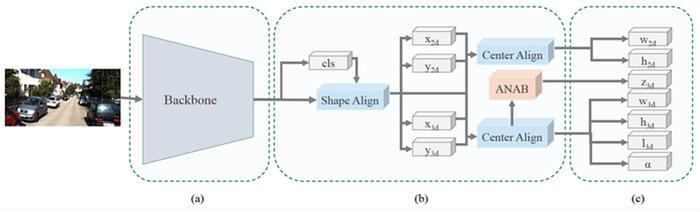
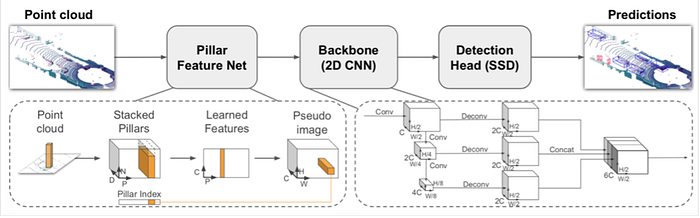
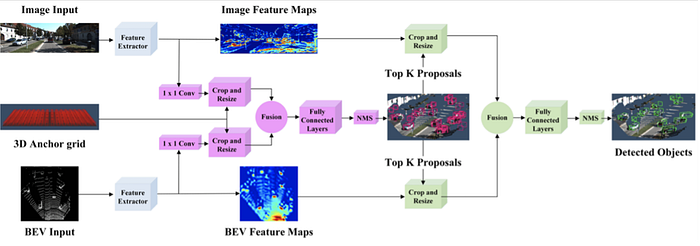
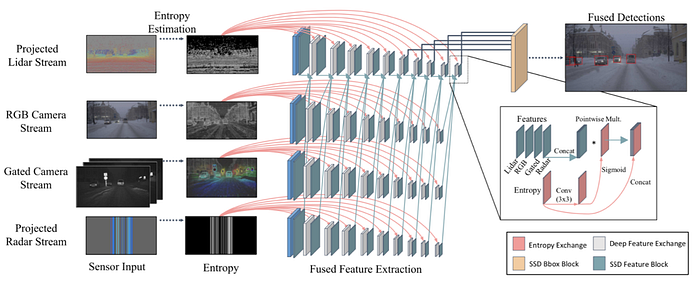
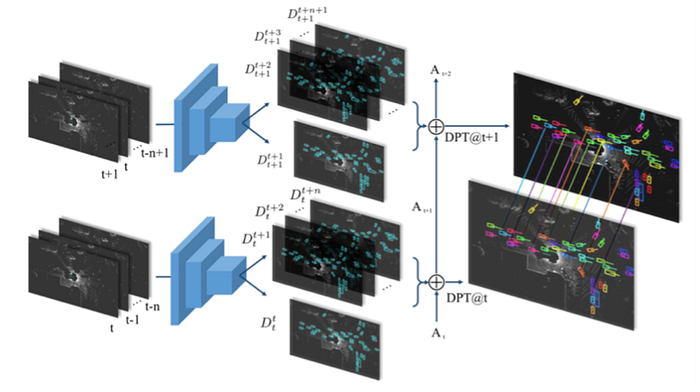
2)Mapping-Localization: semantic map, feature design, map update/online mapping, SLAM, pose estimation and odometry etc.
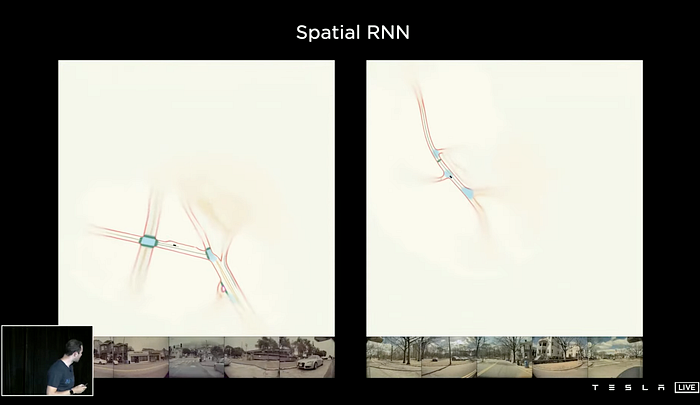

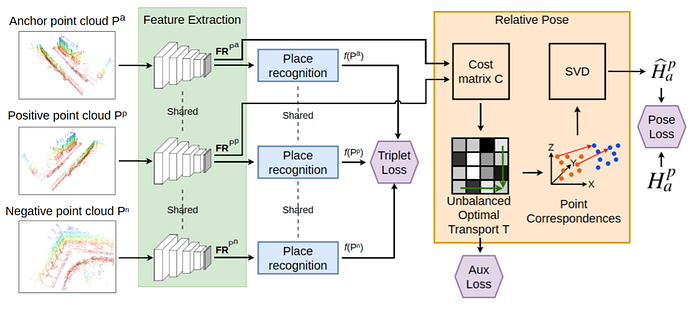

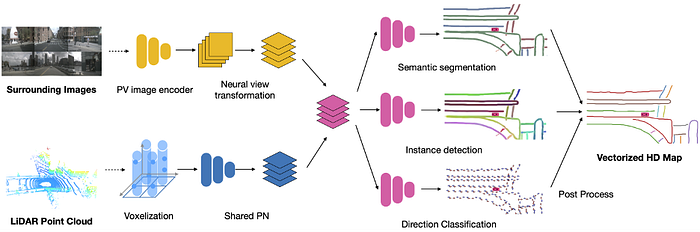
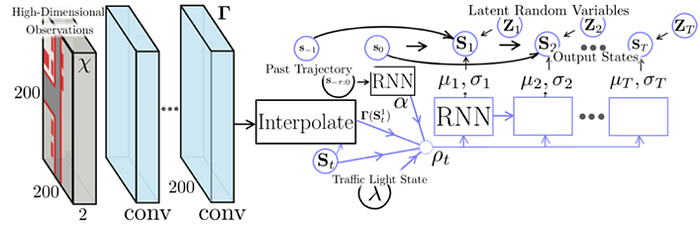
3)Prediction: trajectory forecasting, agent behavior & interaction, multimodal, and perception-prediction etc.

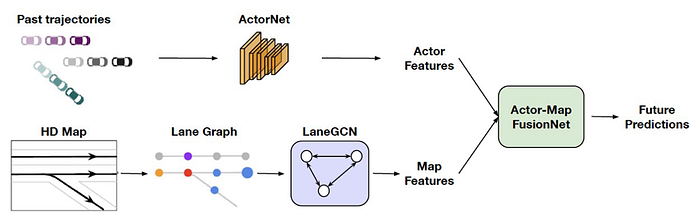
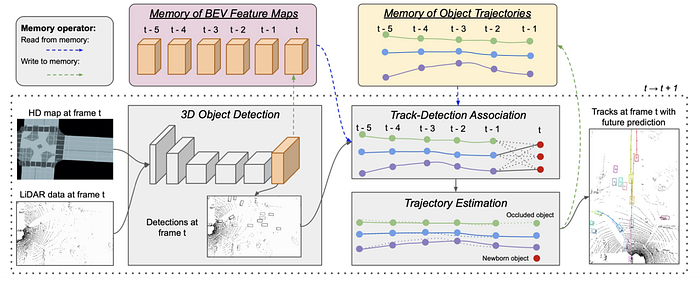

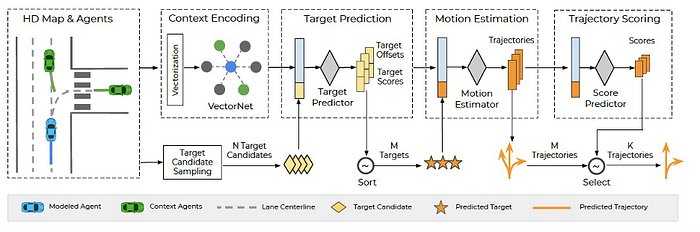
4)Planning: reinforcement learning, imitation learning, inverse reinforcement learning, localization & personalization of planning (aggressive or conservative), prediction-planning, and mapping-localization-prediction-planning etc.
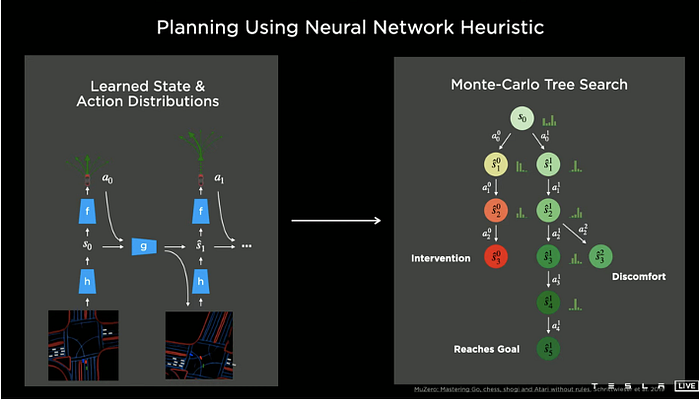
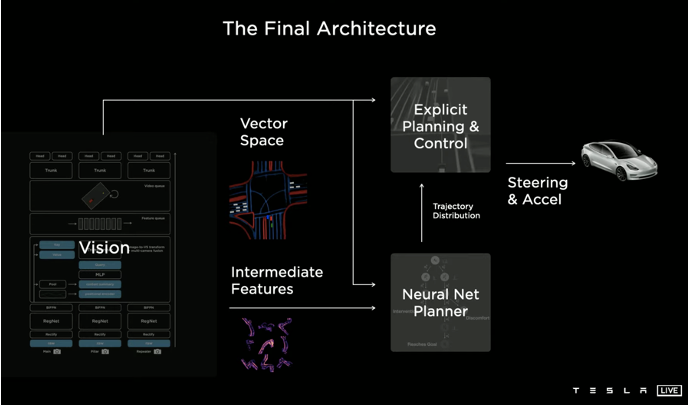
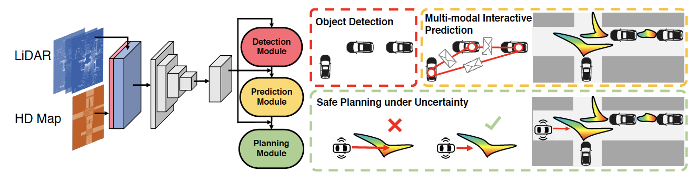
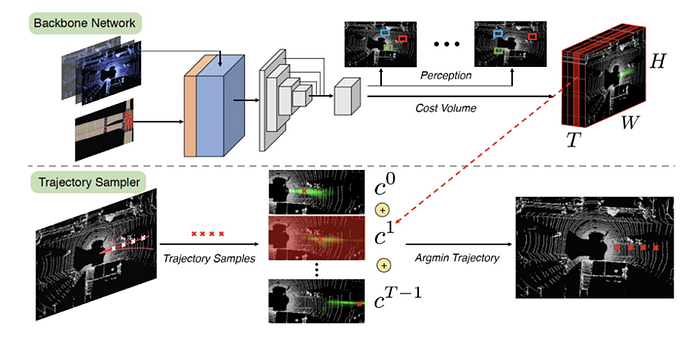
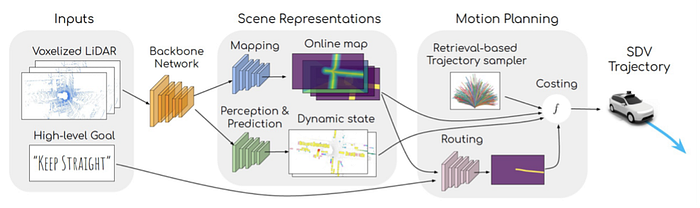
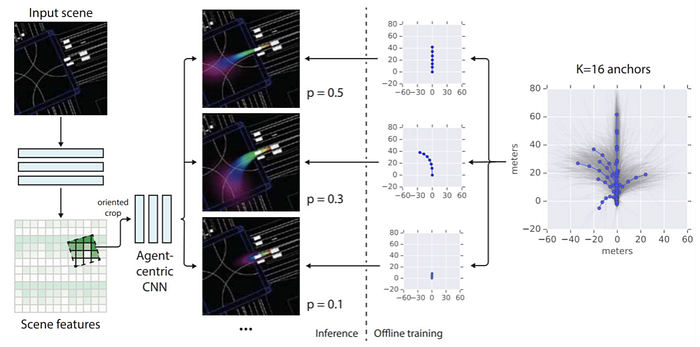
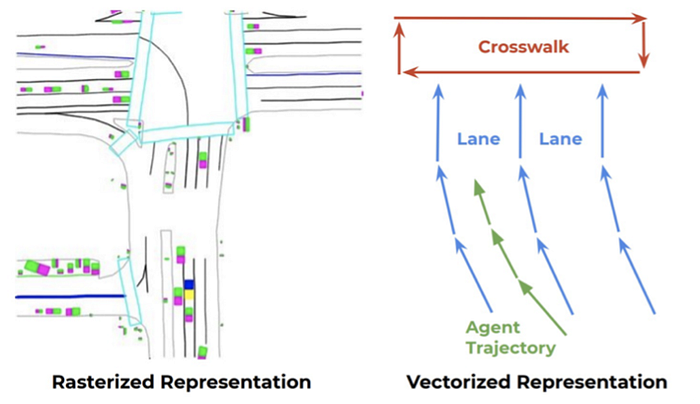
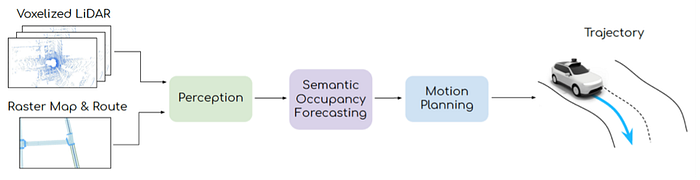
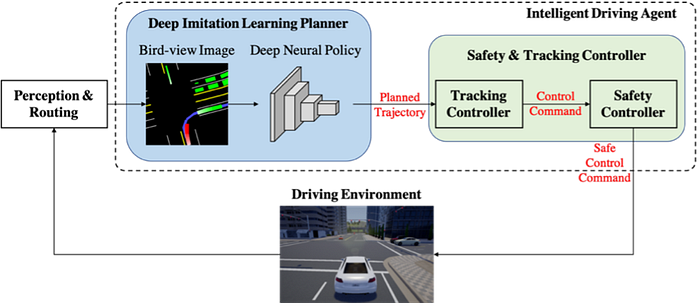
5)Control: reinforcement learning, imitation learning, inverse reinforcement learning, and planning-control etc.
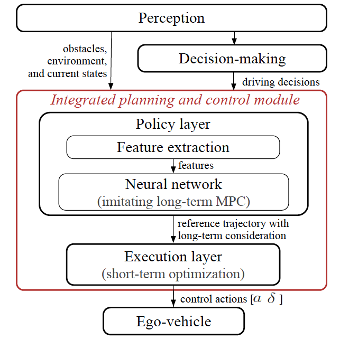
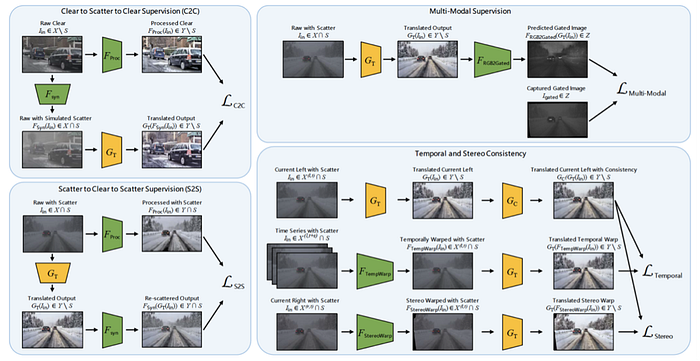
6)Sensor Data Preprocessing: pollution/dust detection, defogging, deraining, desnowing, denoising, and enhancement etc.
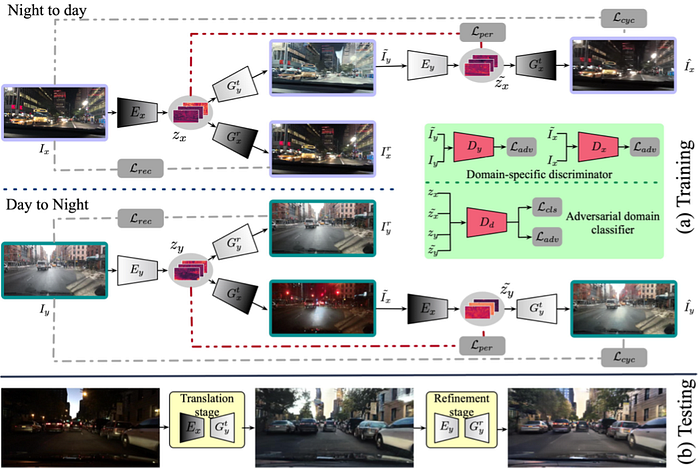
7)Simulation: vehicle/human, sensor, traffic, road and envirnment modeling etc.
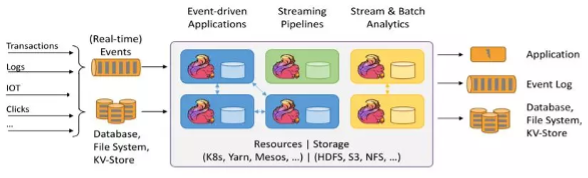
2 Cloud computing infrastructure and big data processing
There are some public cloud services for use, like Amazon AWS, Google Cloud and Microsoft Azure etc. Below it shows a AWS reference data service platform for autonomous driving.
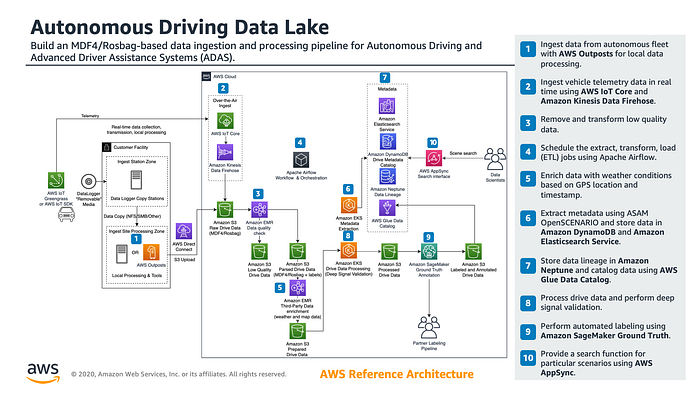
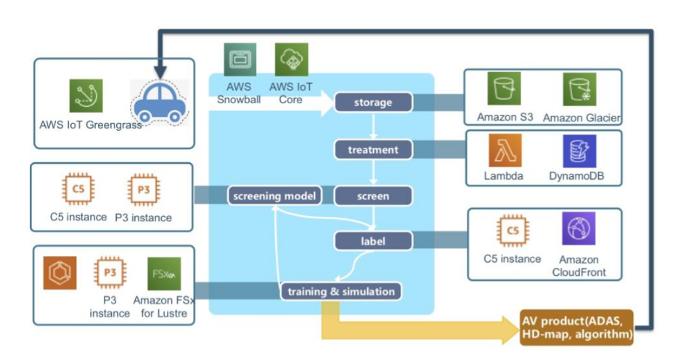
AWS supports a startup at China, Momenta, for its autonomous driving development, shown as (Note: AWS IoT Greengrass provides edge computing with machine learning inference capabilities for real-time processing of local rules and events in the vehicle while minimizing the cost of transmitting data to the cloud.)
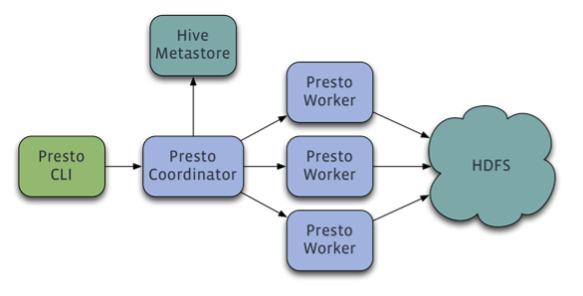
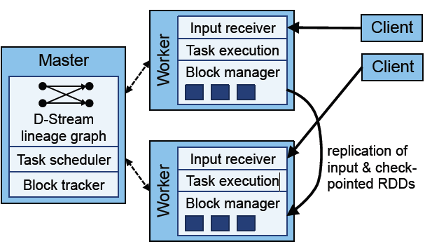
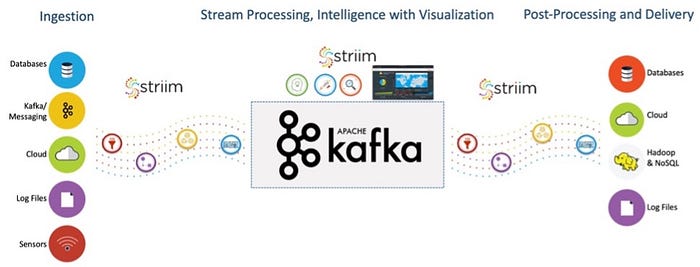
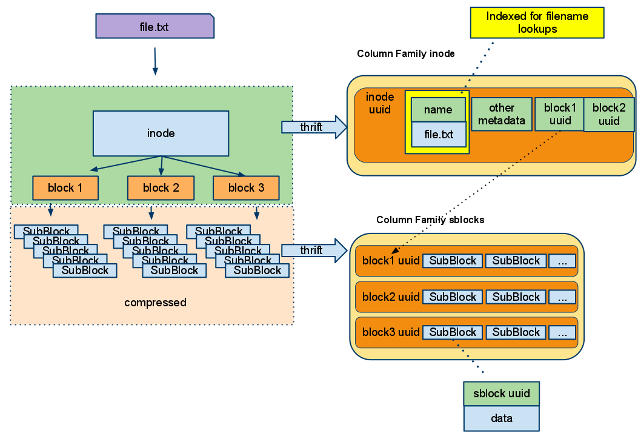
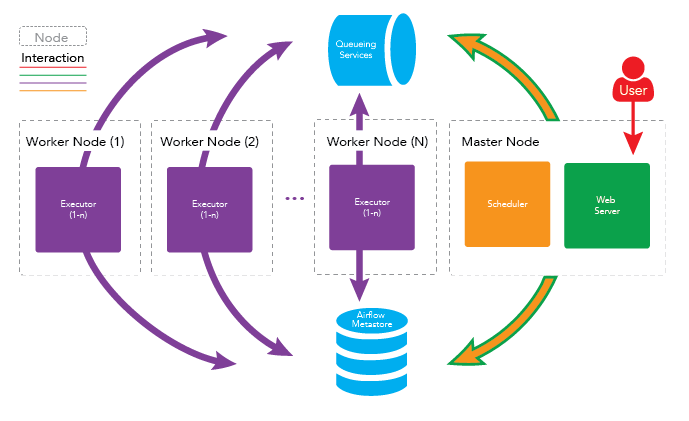
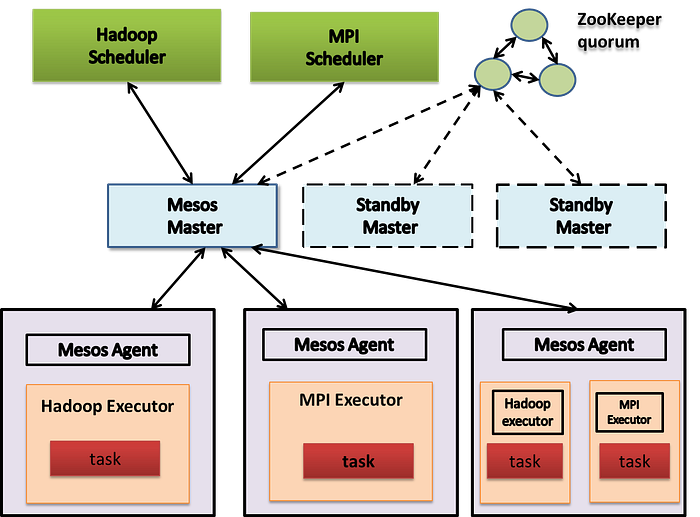
There are some well known open source big data processing tools in cloud service: Presto, Apache Spark/Flint, Apache Kafka, Apahce Cassandra, Apche Hbase, Apache Hudi, Apache Airflow, Apache Mesos and Kubernetes etc.



3 Annotation tools for training data
There are manual, semi-automatic or full automatic tools for annotation. For exxamples:
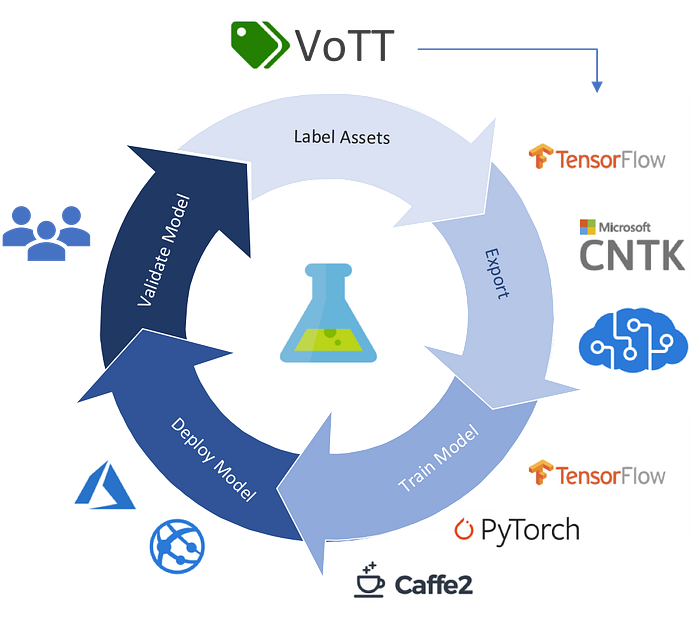
https://github.com/microsoft/VoTT
https://github.com/halostorm/PCAT_open_source
https://github.com/openvinotoolkit/cvat
https://github.com/cvondrick/vatic
https://github.com/walzimmer/3d-bat
https://github.com/hasanari/sane
https://github.com/bernwang/latte
There are some papers discussing automatic annotation tools, as


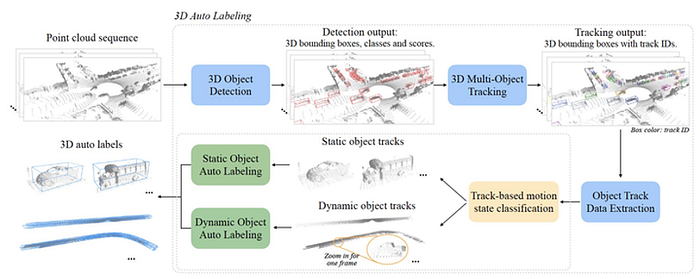
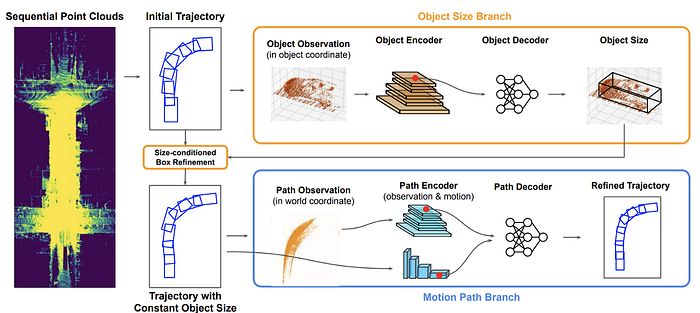
Below is nvidia’s E2E labeling workflow:

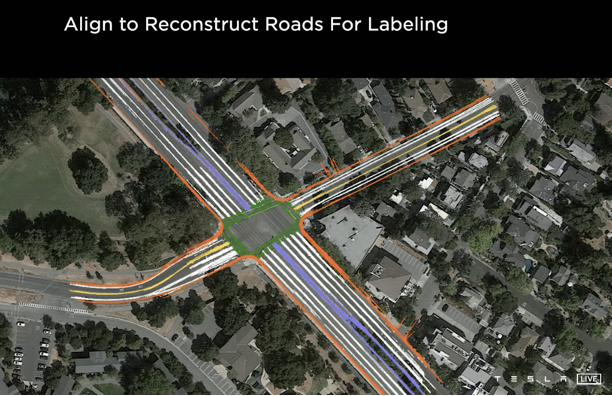
This is Tesla’s AutoLabeling tool:


Also Tesla builds a in-house labeling team (more than 1000 people)for 4-D labeling:

BTW, visualization tools are used for viewing/debugging/replaying the data, besides of annotation. Uber gives a open sourced visualization tool, Autonomous Visualization System (AVS): avs.auto

XVIZ is the Protocol for Real-Time Transfer and Visualization of Autonomy Data as:
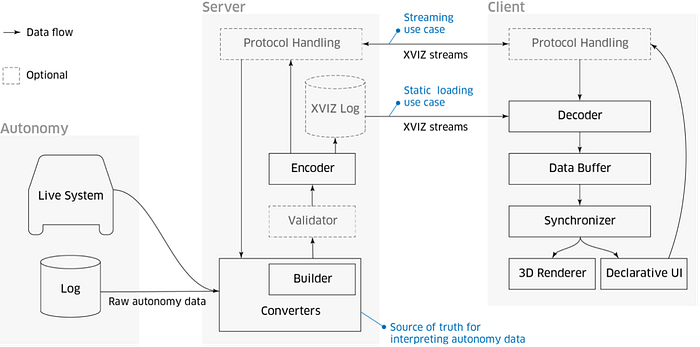
Besides, streetscape.gl is a visualization toolkit for autonomy and robotics data encoded in the XVIZ protocol. It offers a collection of composable React components that let users visualize and interact with XVIZ data.
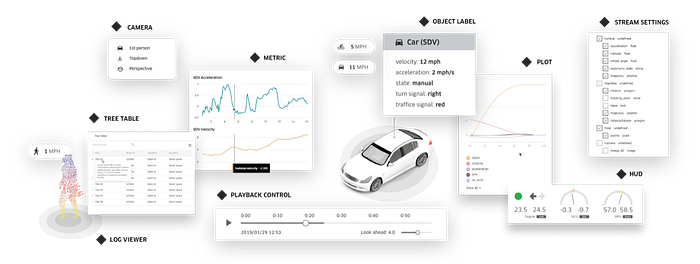
4 Large scale model training platform
There are open deep learning training platforms, previously as Caffe, now the most popular ones are Tensorflow and PyTorch.
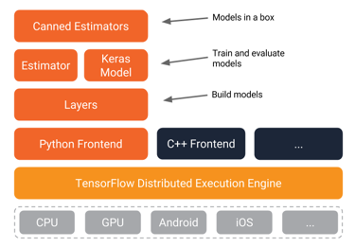
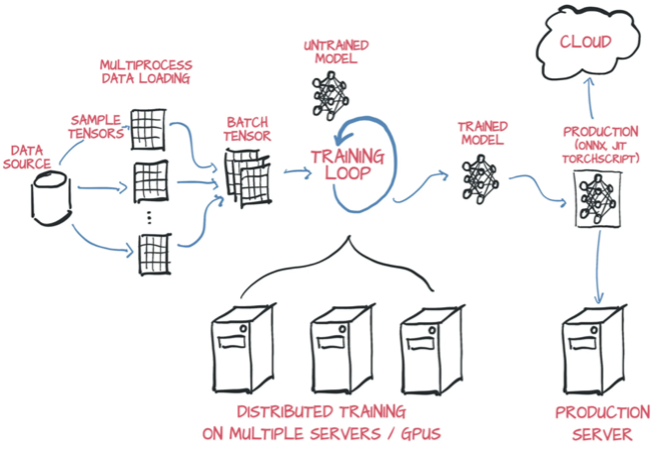
There are three kinds of parallelisms — Data, Model, and Hybrid parallelism. For data parallelism, the input data is partitioned and distributed to multiple machines which each machine has an identical whole DL model. For model parallelism, the model is partitioned and distributed to multiple machines while each machine processes the same whole data. For hybrid parallelism, both the model and data are partitioned and distributed to machines. The data parallelism is most frequently used in current deep learning.
There are two different ways to update weights of DL models in training phase — centralized and decentralized deep learning.
In the centralized DL, there are central components called parameter servers (PS) to store and update weights.

In the decentralized DL, there are no central components, parameter servers. Their accuracies are more susceptible to different initial values of weights and different training speed of individual workers than the ones in the centralized DL.
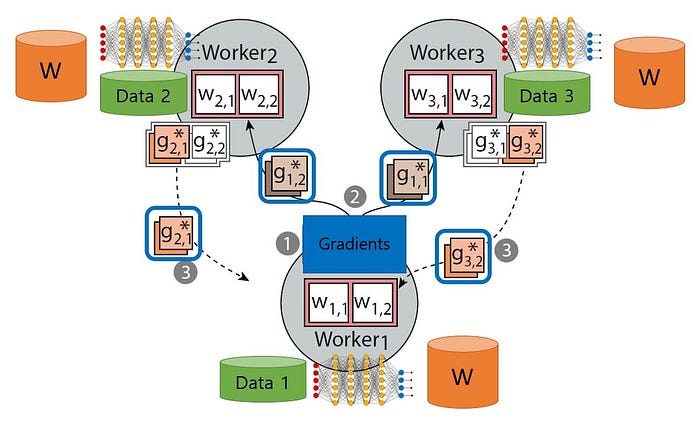
There are two common ways of distributing training with data parallelism.
Synch training (all-reduce architecture): All devices (GPUs) train over different slices of input data in sync and aggregating gradient at each step.there are three common strategies comes under sync training
Async Training (parameter server architecture): all workers are independently training over the input data and updating variables asynchronously.
tf.distribute.Strategy is a TensorFlow API to distribute training across multiple GPUs, multiple machines or TPUs. Using this API, users can distribute existing models and training code with minimal code changes.
tf.distribute.Strategy can be used with a high-level API like Keras, and can also be used to distribute custom training loops .
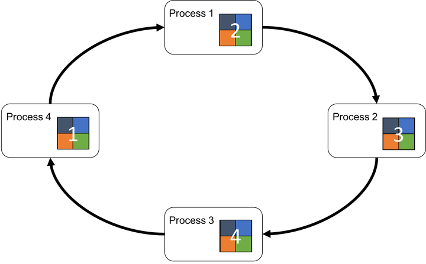
There are two distributed ML training systems, called Parameter Server Architecture (PS) and Ring -AllReduce Architecture, shown as
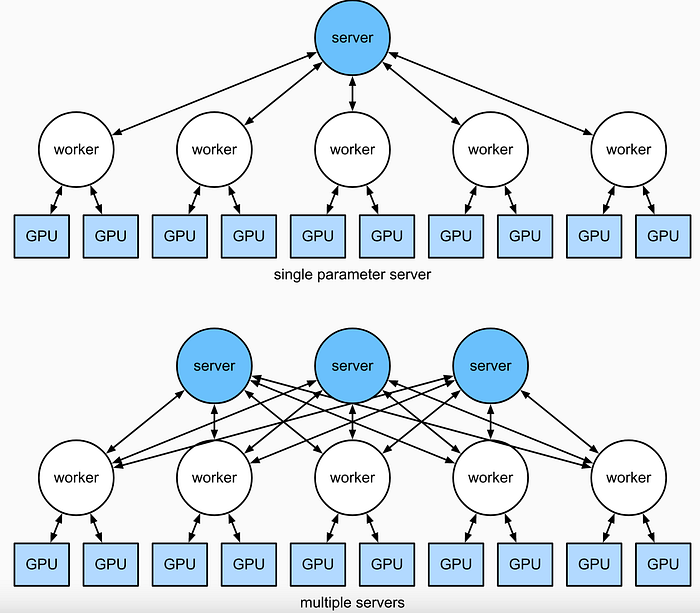
Parameter server training is a common data-parallel method to scale up model training on multiple machines. A parameter server training cluster consists of workers and parameter servers. Variables are created on parameter servers and they are read and updated by workers in each step.
Efficient all-reduce algorithms are used to communicate the variable updates across the devices. All-reduce aggregates tensors across all the devices by adding them up, and makes them available on each device. It’s a fused algorithm that is very efficient and can reduce the overhead of synchronization significantly.
PyTorch DDP utilizes some techniques that are engineered to increase performance based on practice. These techniques are gradient bucketing (adds a hyper-parameter, bucket, to launch each all_reduce. Small tensors bucket into one all_reduce operation), overlapping communication with computation (which depends on when the first bucket gets ready and the backward computation order), and skipping synchronization.
Horovod is a distributed deep learning training framework for TensorFlow, Keras, PyTorch, and Apache MXNet. The goal of Horovod is to make distributed deep learning fast and easy to use. Horovod is a stand-alone Python library for data parallelism using an optimized ring_allreduce collective and a tensor fusion algorithm that works on top of another DL framework.
Horovod completely replaces the parameter server-based optimizer of TensorFlow which underutilizes the resources because of its communication overhead with its synchronous optimizer. Horovod supports model partitioning but does not support model or pipeline parallelism, so it can train only models that fit into a single device (maybe with multiple GPUs).
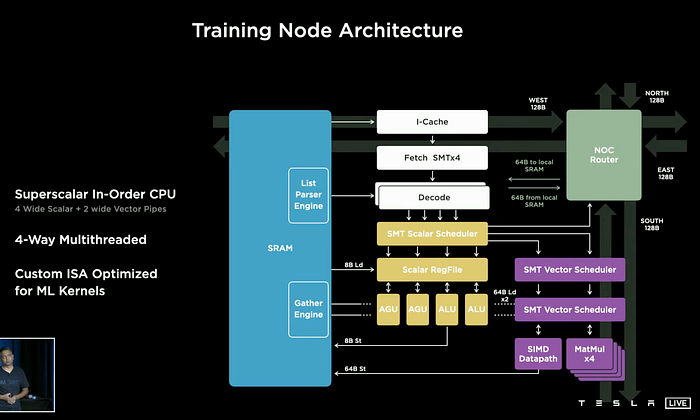
At last,let's see Tesla‘s large scale training platform Dojo:

5 Model Testing and Verification
There are different levels of methods for ADS testing and verification.
1)Testing from simulation
We have seen some open sources like Intel Carla, Microsoft AirSim and LG SVL etc.
Some nice work in ADS simulation are reported in papers as


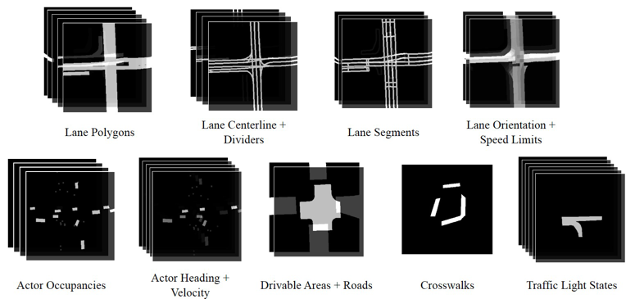



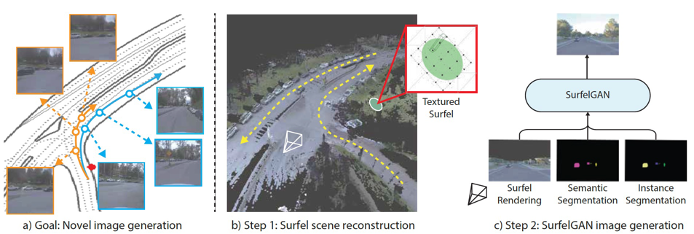
The testing for MIL/SIL/HIL/VIL are realized by some commercial simulation tools like Prescan, VTD, CarSim and Carmaker etc.
Below is Tesla‘s simulation platform:

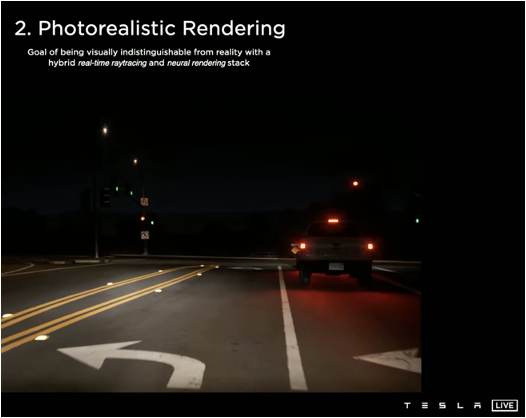



2)Testing from closed driving district

3)Testing from open driving area

4) Testing from users (such as Tesla’s shadow mode)


Below is nvidia’s framework for AV fleet scale deployment:
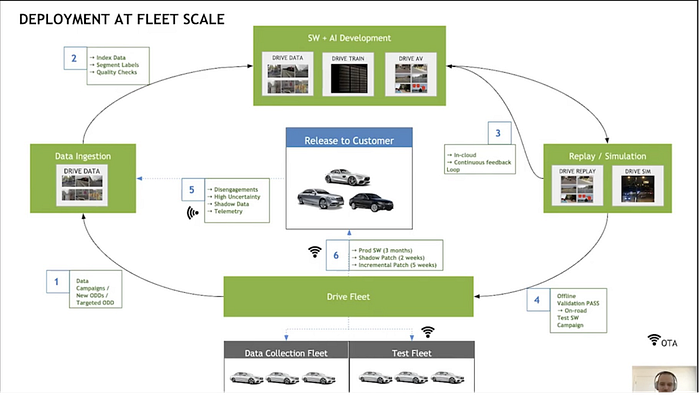
6 Related machine learning techniques
There are some ML methods useful for the data closed loop platform:
Active learning
OOD detection & Corner case detection
Data augmentation/Adversarial learning
Transfer learning/Domain adaptation
AutoML/Meta-learning
Semi-supervised
Self-supervised
Zero/Few shot learning
Continual learning/Open world learning
Let’s introduce one by one as following.
1)Active learning
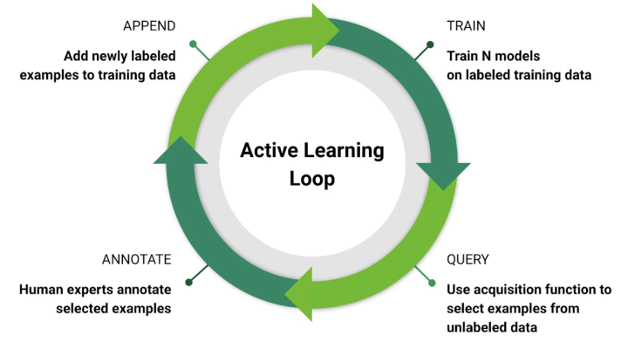
The goal of active learning is to find effective ways to choose data points to label, from a pool of unlabeled data points, in order to maximize the accuracy. Active learning is typically an iterative process in which a model is learned at each iteration and a set of points is chosen to be labelled from a pool of unlabeled points using some heuristics.
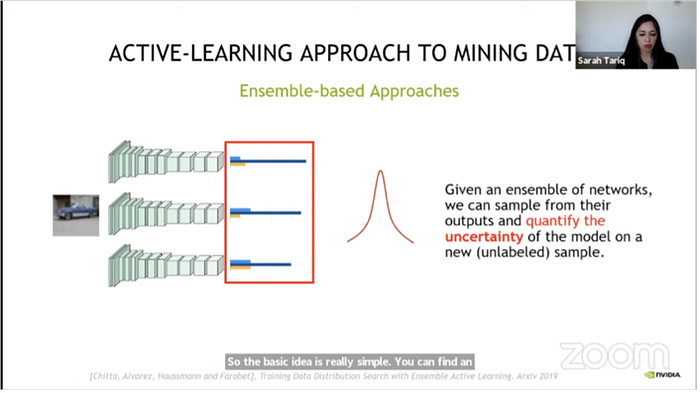
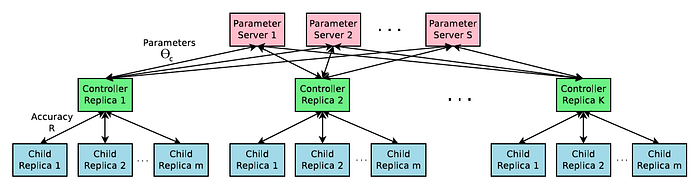
Bayesian active learning methods typically use a non-parametric model like Gaussian process to estimate the expected improvement by each query or the expected error after a set of queries.Uncertainty based methods, which try to find hard examples using heuristics like highest entropy, and geometric distance to decision boundaries. Below is nvidia’s work with ensemble-based methods:
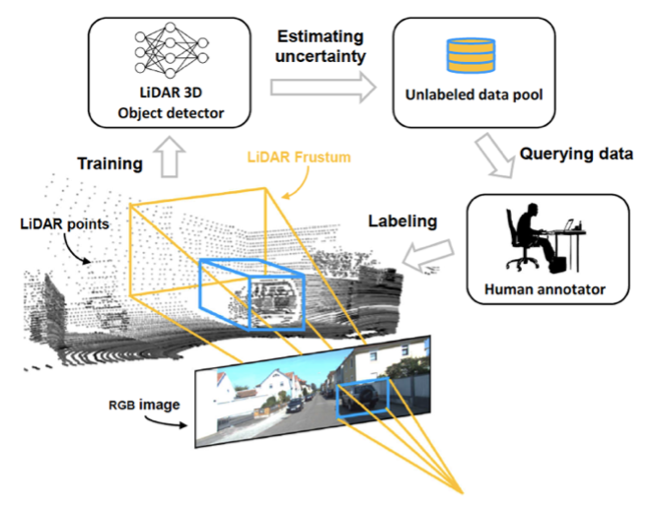
Other examples are:
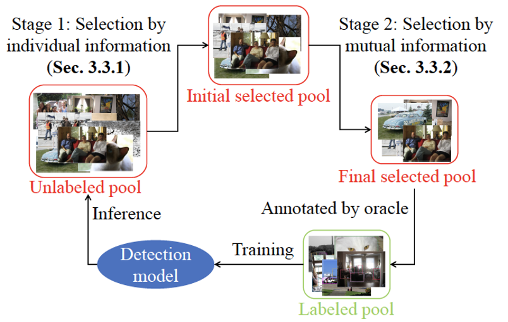
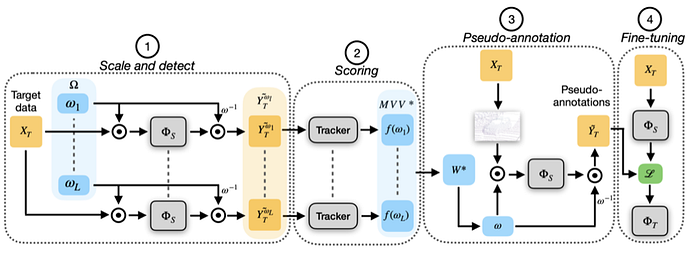
2)OOD detection & Corner case detection
NNs may fail on input data not well represented by the training dataset, known as out-of-distribution (OOD) data. A mechanism to detect OOD samples based on uncertainty estimate is important in safety-critical applications,in order to trigger a safe fallback mode.
There are two sources of uncertainty, called aleatoric and epistemic uncertainties.
The challenging task of corner case detection, aims at detecting these unusual situations, which could become critical, and to communicate this to the autonomous driving system (online use case). Such a system, however, could be also used in offline mode to screen vast amounts of data and select only the relevant situations for storing and (re)training machine learning algorithms.
Some example work are given:
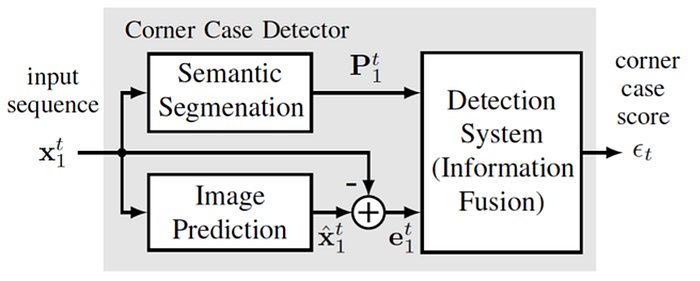
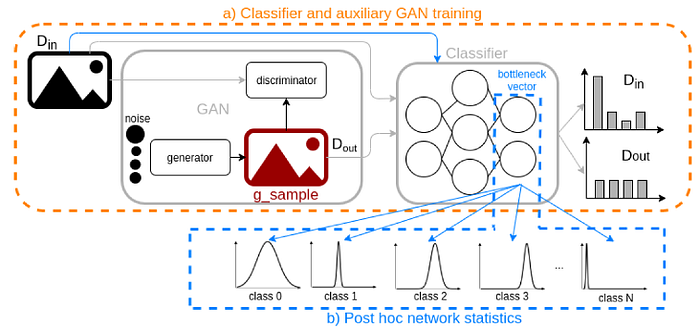

3)Data augmentation/Adversarial learning
Overfitting refers to the phenomenon when a network learns a function with very high variance such as to perfectly model the training data. Data Augmentation encompasses a suite of techniques that enhance the size and quality of training datasets such that better Deep Learning models can be built using them.
Image augmentation algorithms include geometric transformations, color space augmentations, kernel filters, mixing images, random erasing, feature space augmentation, adversarial training, generative adversarial networks, neural style transfer, and meta-learning.
Adversarial training can be an effective method for searching for augmentations. By constraining the set of augmentations and distortions available to an adversarial network, it can learn to produce augmentations that result in misclassifications, thus forming an effective search algorithm.
Some recent work are shown below:
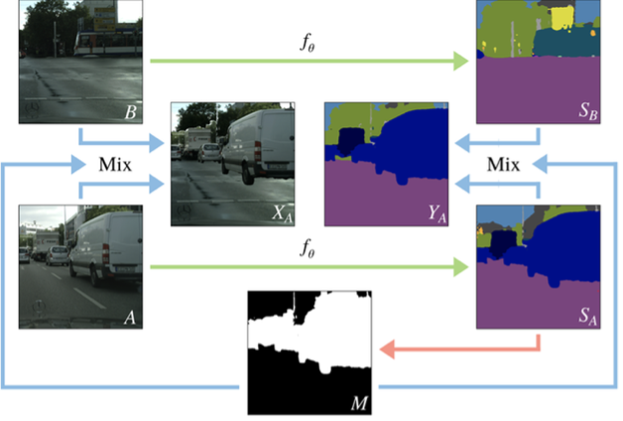
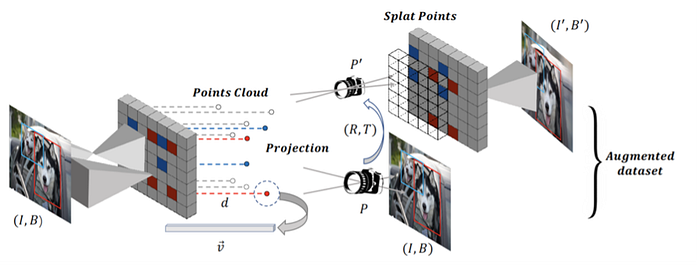
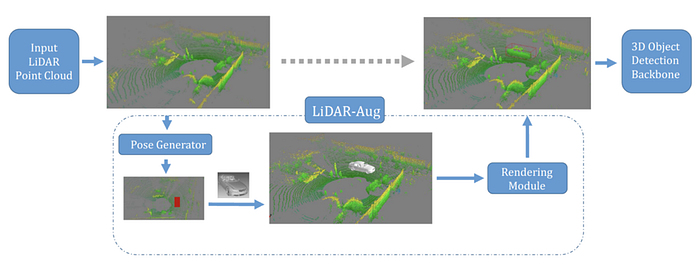
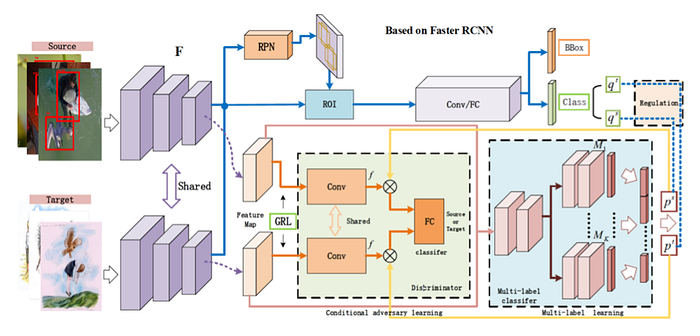
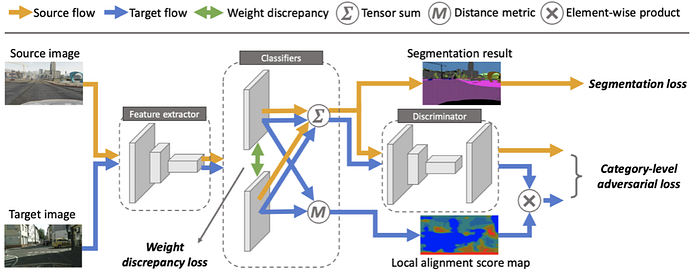
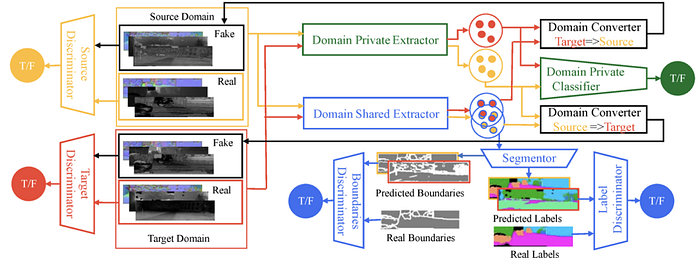
4)Transfer learning/Domain adaptation
Transfer learning (TL) relaxes the hypothesis that the training data must be independent and identically distributed (i.i.d.) with the test data, which motivates us to use transfer learning to against the problem of insufficient training data.
Domain adaptation (DA) is a particular case of transfer learning (TL) that utilizes labeled data in one or more relevant source domains to execute new tasks in a target domain.
Some latest work are:
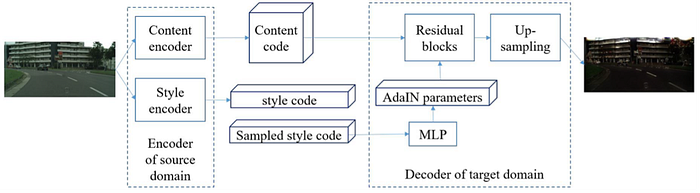
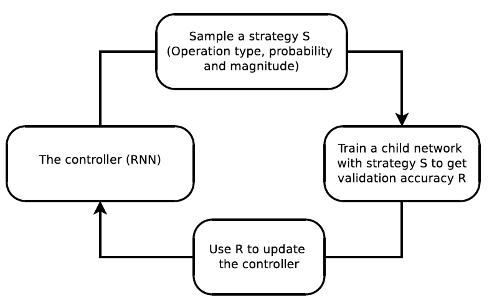
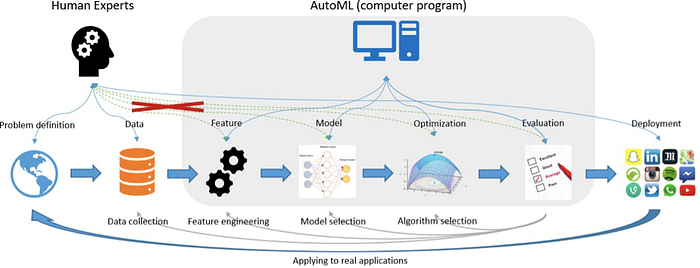
5)AutoML/Meta-learning
There are still several aspects in ML application systems, which need human intervention and interpretability in order to make the correct decisions that can enhance and affect the modeling steps.
These aspects belongs to two main building blocks of the machine learning production pipeline: Pre-Modeling and Post-Modeling.
Pre-Modeling is an important block of the machine learning pipeline that can dramatically affect the outcomes of the automated algorithm selection and hyper-parameters optimization process. The pre-modeling step includes a number of steps including data understanding, data preparation and data validation.
Post-Modeling block covers other important aspects including the management and deployment of produced machine learning model which represents a corner stone in the pipeline that requires the ability of packaging model for reproducibility.
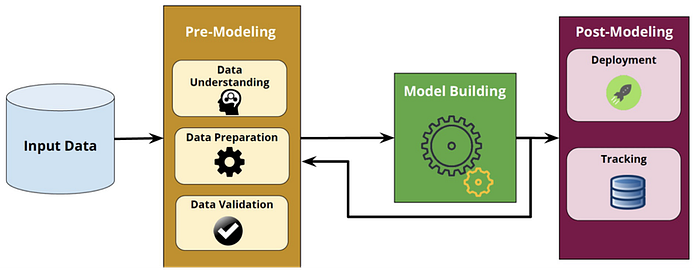
Automated Machine Learning (AutoML) is designed to reduce the demand for data scientists and enable domain experts to automatically build machine learning applications without much requirement for statistical and machine learning knowledge.
NAS (Neural Architecture Search) aims at generating a robust and wellperforming neural architecture by selecting and combining different basic components from a predefined search space. It is summarized from two perspectives: model structure type and model structure design by hyperparameter optimization (HPO).
Meta-learning is closely related to AutoML since they share the same objectives of study, namely the learning tools and learning problem.
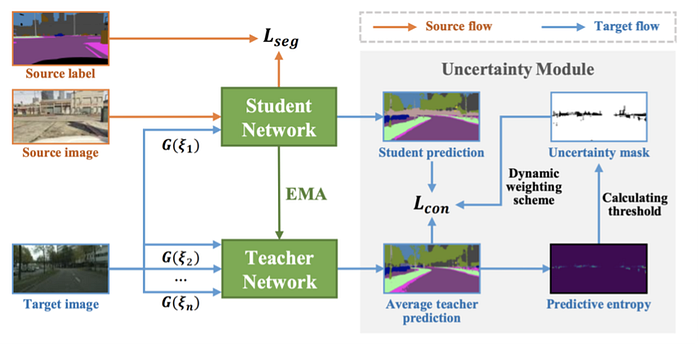
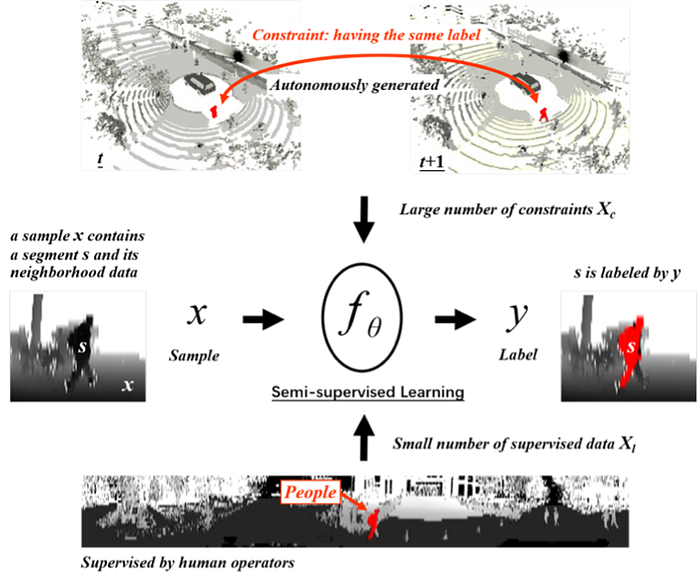
6)Semi-supervised learning
Self-supervised Learning is to leverage the unlabeled data to produce a prediction function with trainable parameters, that is more accurate than what would have been obtained by only using the labeled data.
There are typical self-supervised learning methods:
“Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks”
“Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results“
“Self-training with Noisy Student improves ImageNet classification“
Below some new methods are proposed:

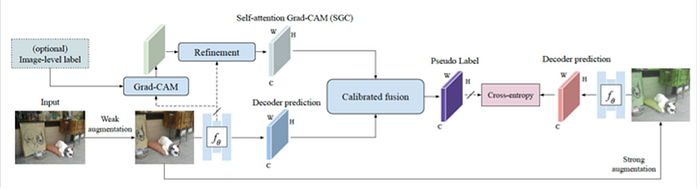
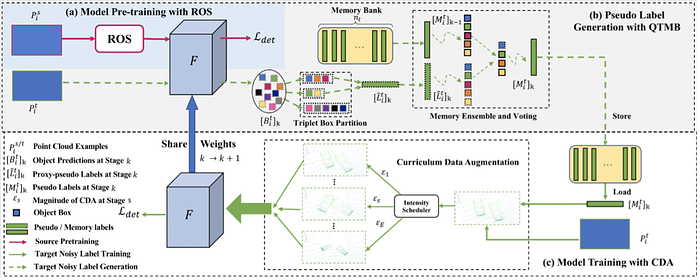
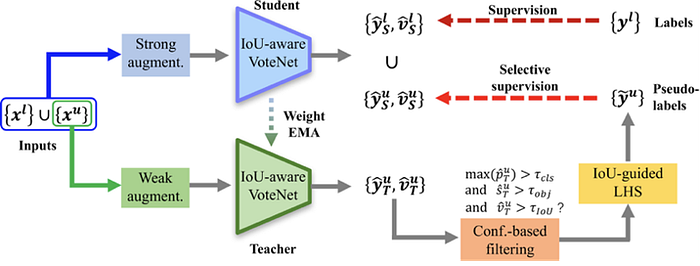
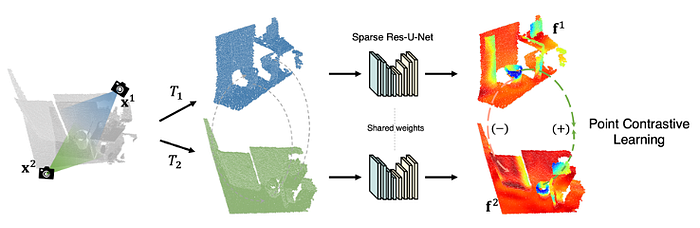
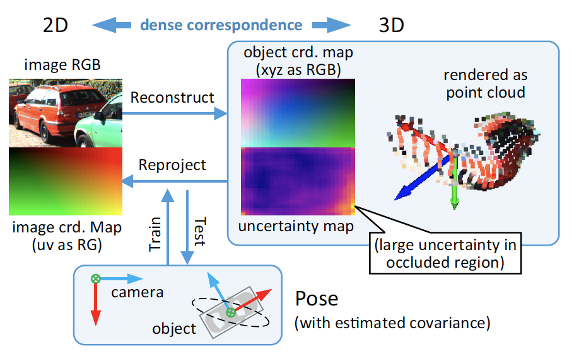
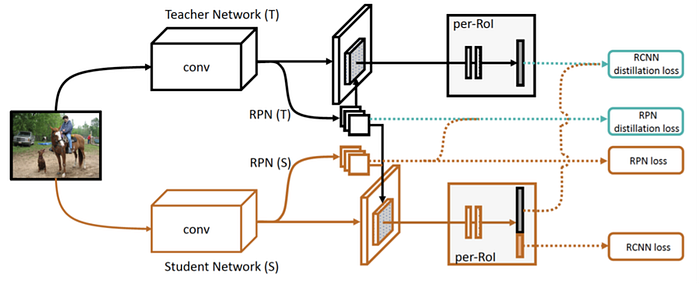
7)Self-supervised learning
Self-supervised learning viewed as a branch of unsupervised learning, which aims at recovering, not discovering. They are categoried as: generative, contrastive, and generative-contrastive (adversarial).
Self-supervised uses a pretext task to learn representations on unlabeled data. The pretext task is unsupervised but the learned representations are often not directly usable for image classification and have to be fine-tuned. Therefore, self-supervised learning can be interpreted either as an unsupervised, a semi-supervised or a strategy of its own.
Some well-known self-supervised learning methods are:
“SimCLR-A Simple framework for contrastive learning of visual representations“
“Momentum Contrast for Unsupervised Visual Representation Learning“
“Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning“
“Deep Clustering for Unsupervised Learning of Visual Features“
“Unsupervised Learning of Visual Features by Contrasting Cluster Assignments“
Below we list some latest work as:
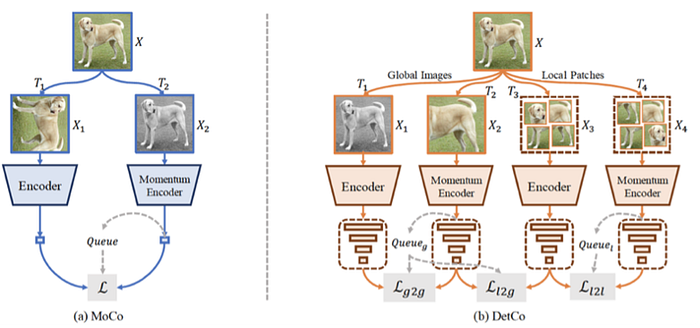
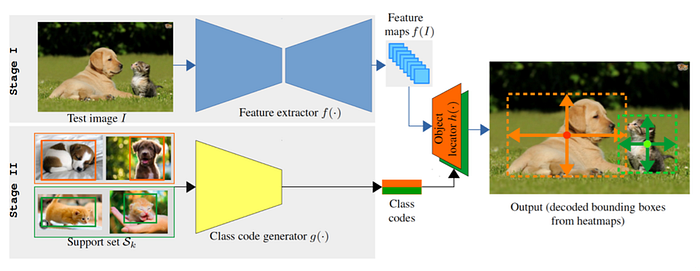
8)Zero/Few shot learning
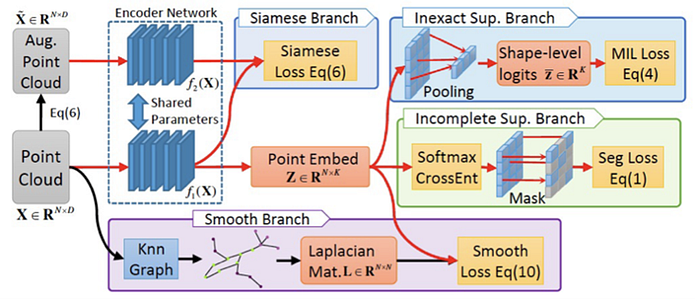
Zero-shot learning (ZSL) aims to recognize objects whose instances may not be seen during training. Zero shot learning belongs to transfer learning: the source feature space is of training instances, and the target feature space is of testing instances. They are the same. The label spaces are different, seen set and unseen set.
Few-Shot Learning (FSL) comes for learning from limited supervised information to get the hang of the task. FSL can be supervised learning, semi-supervised learning and reinforcement learning, depending on what kind of data is available apart from the limited supervised information. Many FSL methods are meta-learning methods, using the meta-learner as prior knowledge.
Some latest work are:


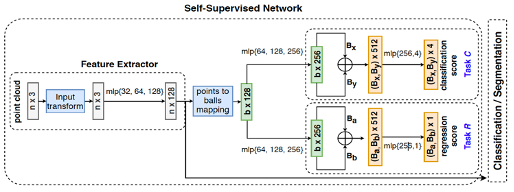
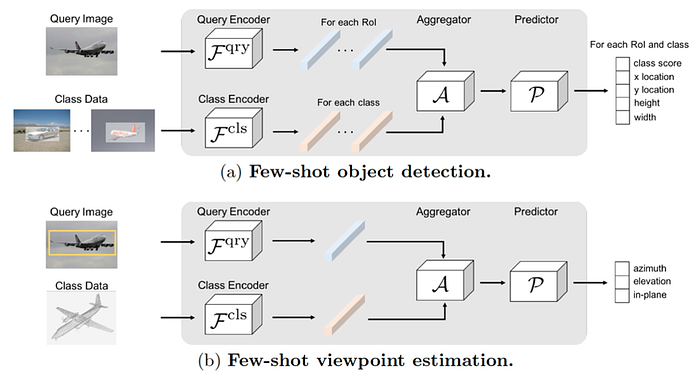
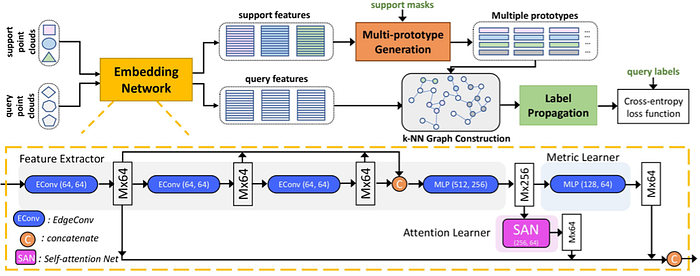
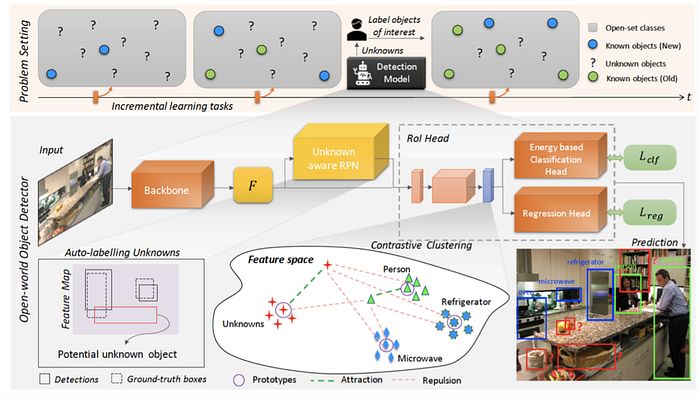
9)Continual learning/Open world learning
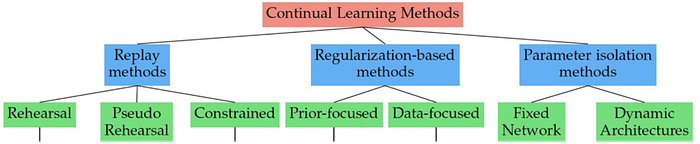
Continual learning can continually accumulate knowledge over different tasks without the need to retrain from scratch. Three families, based on how task specific information is stored and used throughout the sequential learning process:
• Replay methods
• Regularization-based methods
• Parameter isolation methods
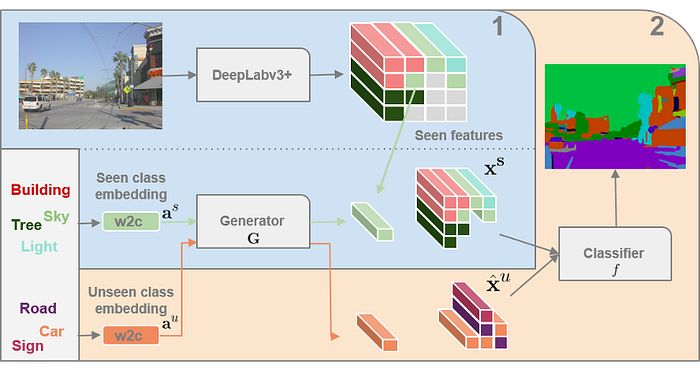
Open set recognition (OSR), where incomplete knowledge of the world exists at training time, and unknown classes can be submitted to an algorithm during testing, requiring the classifiers to not only accurately classify the seen classes, but also effectively deal with unseen ones.
Open world learning can be seen as a sub task of continual learning.
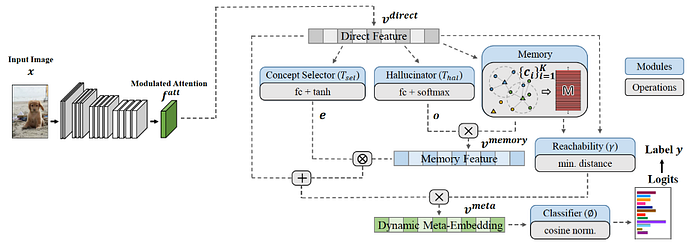
Some recent work are given as

7 Conclusion
In summary, the key in the data closed loop building is the sourceful data. The data driven models or algorithms applied to solve autonomous driving tasks is the base. The trend for this system upgrade depends on:
• Data mode (camera, LiDAR, radar, IMU etc.)
• Data driven model architecture (AutoML)
• Policy to select and use the data (Corner case).
