Twelve Questions about Tesla Autopilot Technologies Exposed at 2021 AI Day
On Aug. 19 2021, Telsa held an AI day, exposing more technologies about Autopilot, from perception, planning, data labeling, simulation, training to computing platform etc.

We welcome Tesla’s generous attitude to introduce its technologies for some reason ( it is mentioned this AI day targeted for recruiting), however there are unknown or unexposed details we are interested to know. In this article, let’s discuss about them, and also compare with the SoTA work from other peers, like Google WayMo, Uber ATG (sold to Aurora already) and Nvidia etc.
1. Does the HD Map work for perception and localization?
We know most of LiDAR-based autonomous driving systems need the HD (High Definition) map, built from LiDAR scanning assisted with IMU and GPS (RTK), such as WayMo, Cruise, Argo, Aurora and Nuro etc. A concern for the HD map is updating, so the work about map change detection or online mapping is investigated.
For the vision-based self driving system, the HD map is also an option. However, the interface with the HD map for localization is more challenging, cause the matching between semantics or features and on-vehicle visual perception is much more difficult than those point cloud or reflection map-based localization methods.
REM (Road Experience Management) or RoadBook from Mobileye is a typical AV map for autonomous driving, more suitable for crowd sourcing:

Nvidia provides its solutions of vision-based localization, however the algorithm is not explained publicly.
https://developer.nvidia.com/drive/drive-mapping

Getting back to Tesla, it has integrated perception with localization and online mapping:
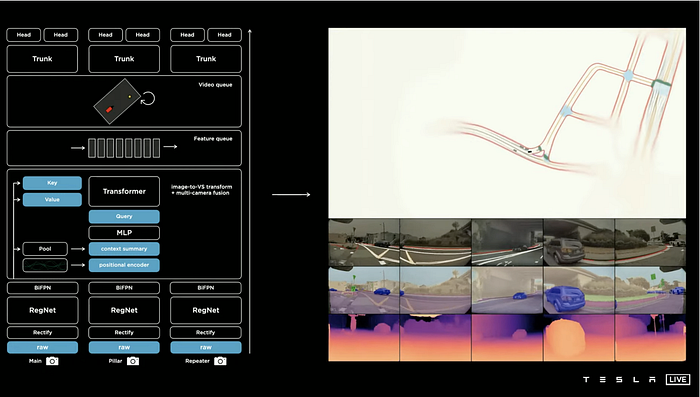
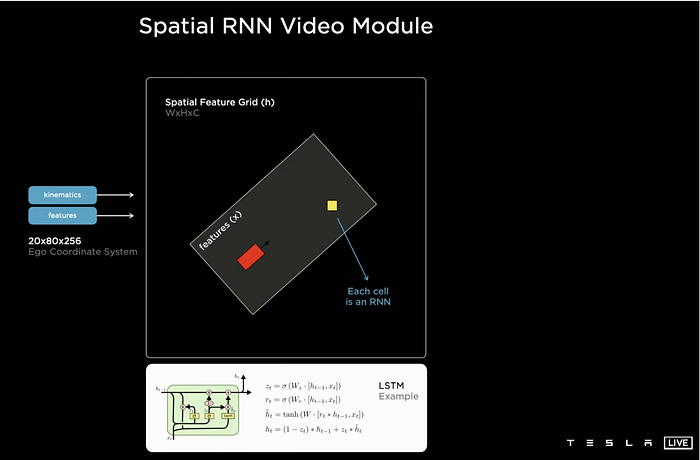
IMU provides kinematics info to the feature queue and the video module (spatial RNN), however accurate alignment still relies on the trained transformer network. Meanwhile, the spatial RNN outputs the online mapping for instantial perception.
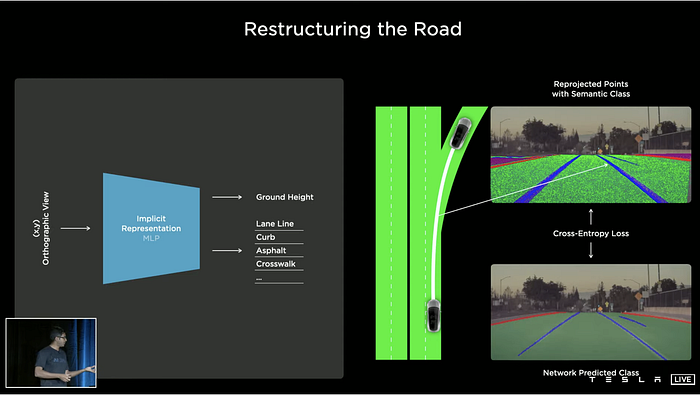
Tesla has developed in-house HD mapping capabilities, which is shown in its auto-labeling tools.
Note: It is claimed this HD mapping-like result is not used for inference, but for annotation of training data only.

Kind of HD Map building demo in AutoLabeling
2 What does the 3-D vector space mean?
As shown in Tesla AI director AK’s presentation, the perception outputs the result in the 3D vector space from the camera input in the image space (8 cameras in total).

As explained before, the image space is not a right outspace for cross-camera fusion, i.e. occupany tracker (OGM), popularly used in the AD industry.

The output in the 3-d vector space from the transformer network looks better:
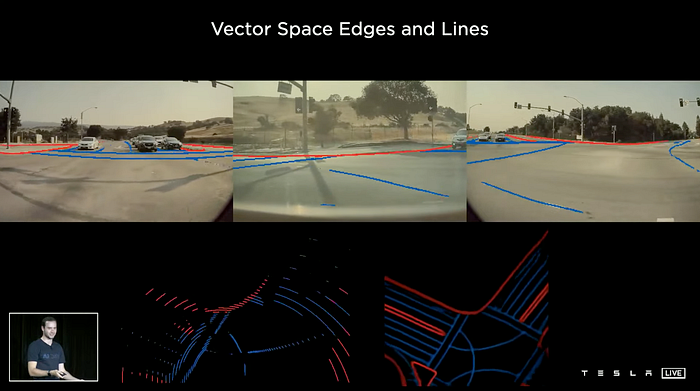
However, the 3-d vector space looks closely related to BEV (bird eye’s view) space. The difference lies in feature maps in BEV can be used for feature queue and video queue, fed into each of the multi-heads, for example velocity estimation.
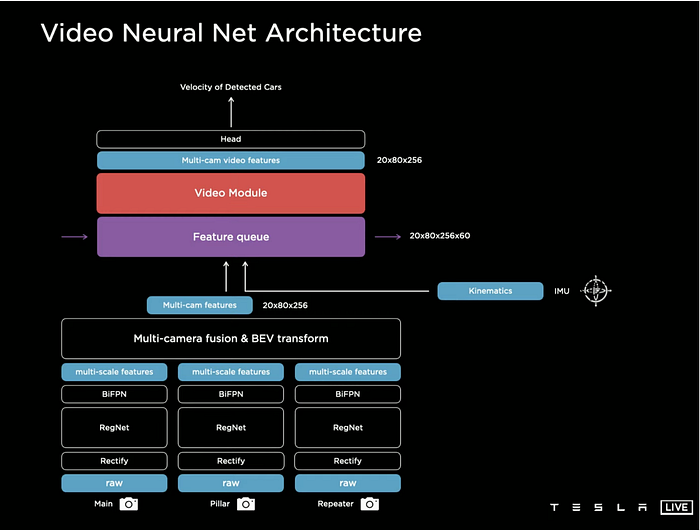
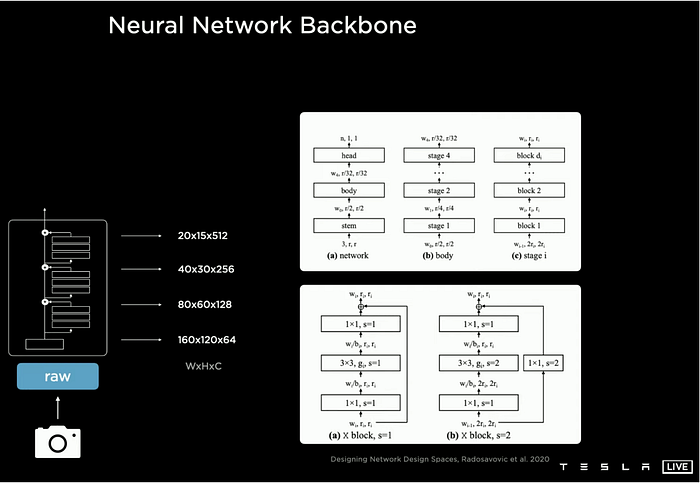
One thing is feature encoding from raw RGB images, Tesla’s perception applies a shared backbone, RegNet, learned from Facebook AI Research (FAIR)’s work
https://arxiv.org/abs/2003.13678
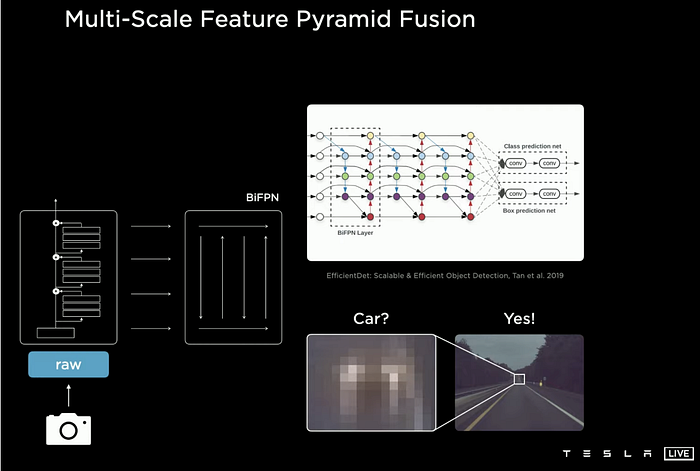
And a shared bottleneck, BiFPN, proposed by Google Research’s work EfficientDet
https://arxiv.org/abs/1911.09070
3 How does the spatial temporal fusion work for perception?
The fusion mechanism is Transformer and spatial RNN (video module).
Transformer has made big performance imrpovement in computer vision, extended from initial work in NLP. Actually it is investigated by some researchers that Transformer is kind of GNN (graph neural network) or GCN (graph convolution network).
A survey of transformer in vision is published at arXiv
https://arxiv.org/abs/2101.01169
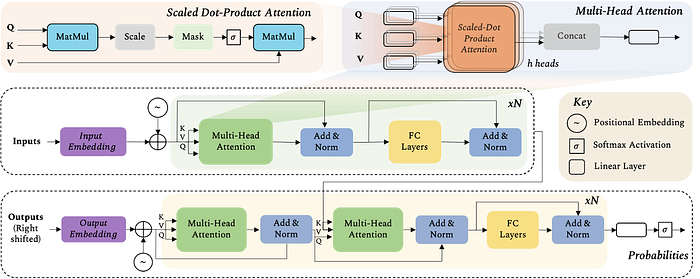
Based on self attention merchanism, the transformer gives the optimized fusion cross 8 cameras, where linear weights of key, value and query are learned, shown in Tesla presentation by AK.
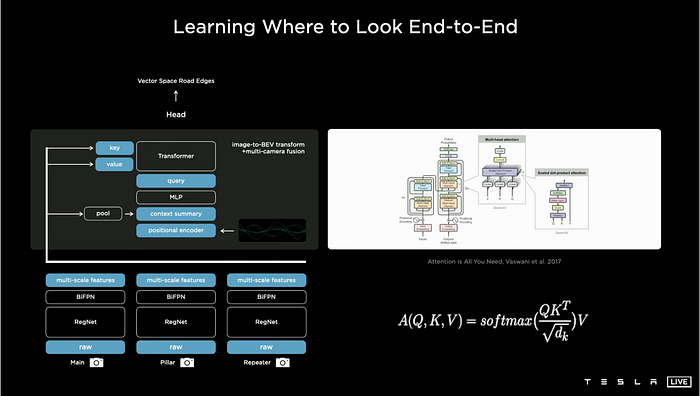
Spatial RNN works by insertion of feature queues, consisting of time-based (every 27ms) and space-based (every 1 meter), to handle the occlusion of moving obstacles and the static landmarks, like RGB traffic lights and lane markings etc.

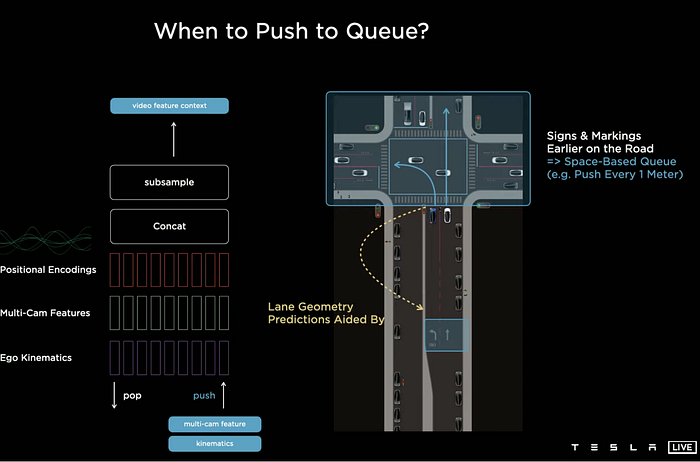
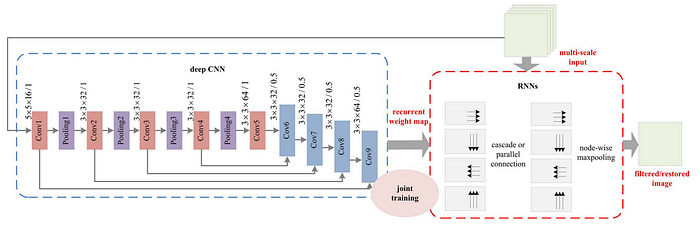
LSTM or GRU is the core of RNN in temporal horizon, and what “spatial” means is invariance to the vehicle pose. A reference work with the similar idea sees an earlier paper written by UC Merced:
https://faculty.ucmerced.edu/mhyang/papers/eccv16_rnn_filter.pdf
Note: this transformer framework is easily extended to sensor fusion, such as inclusion of LiDAR point cloud projection, and radar’s point cloud projection or range-angle map from radar cross section (RCS).
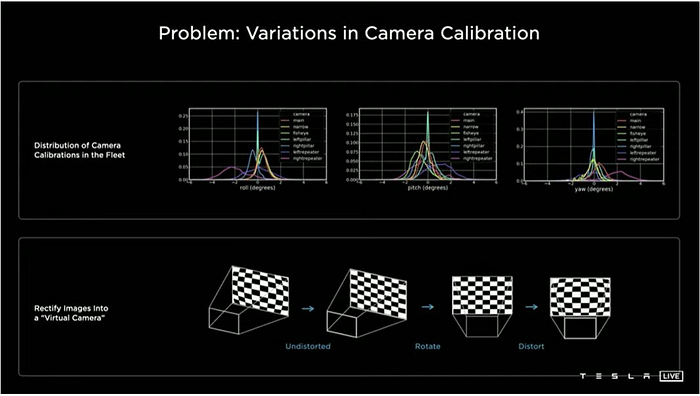
One thing is worth to mention, AK introduced the “rectify” module, which transforms real images to a “virtual camera” image space, avoiding the burden of variations in camera calibration. It is a quite engineering problem, critical for neural network training, in deep learning model generalization.

Let’s see what Mobileye‘s ’Supervision does for multi-camera fusion: it is more like a data fusion result as surround vision and 360 degree environment model/map fusion.
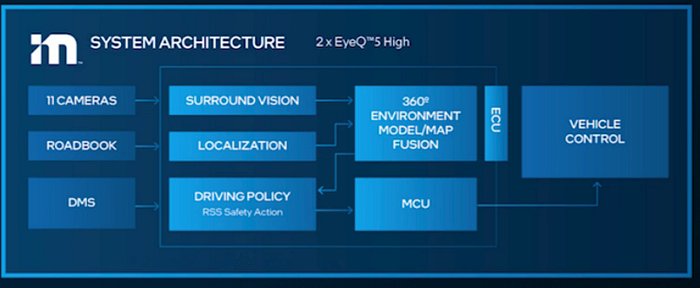


4 What does depth estimation work for perception?
Apparently the transform from the image space to BEV, applied neither the depth map estimated from neural network, nor the IPM (inverse perspective mapping) based on the assumption of the flat road surface. However, it exists two heads for depth and velocity estimation in Autopilot.
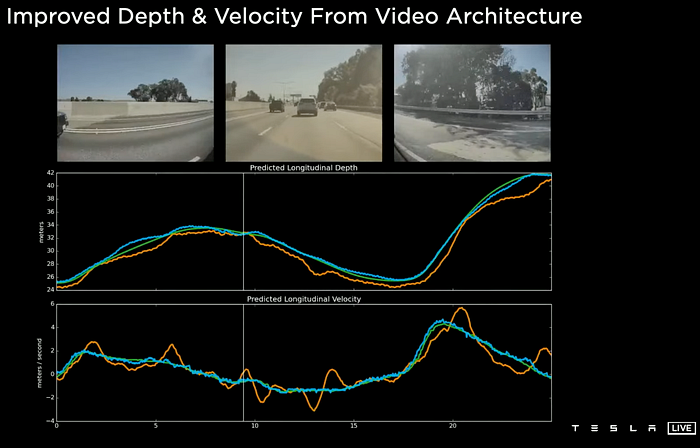
In the auto labeling tools, the depth is used for 3-D reconstruction, as well as the feature flow vectors.
It is worth to mention Telsa’s Multi Task Learning framework (MTL), HydraNet, a multi-head platform with shared backbone and bottleneck:
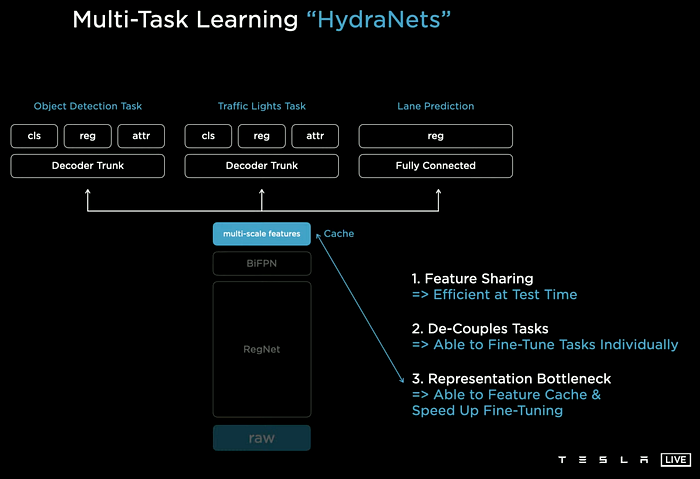
Instead, Mobileye designs a RangeNet for distance estimation and ViDAR (DNN-based Multi-view Stereo) for 3-d reconstruction online:
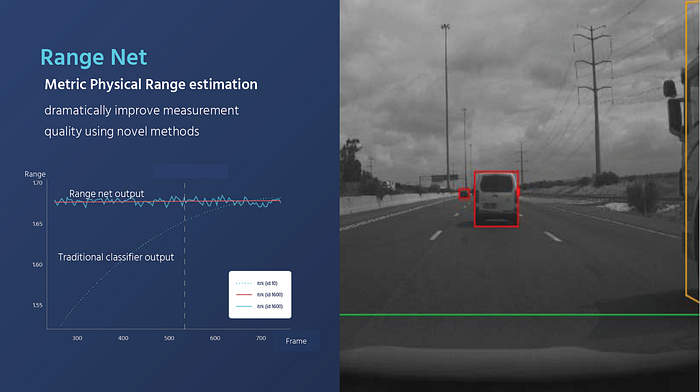

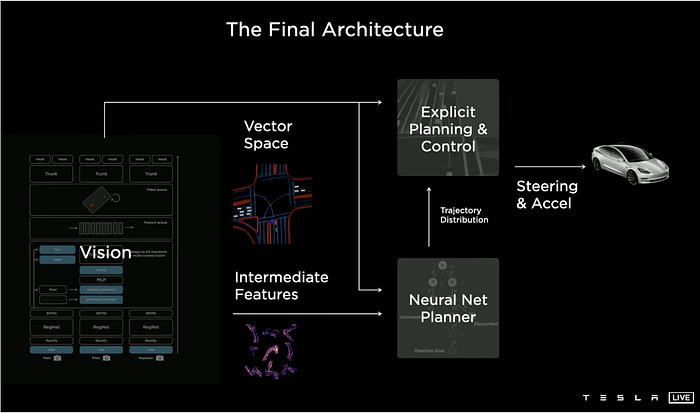
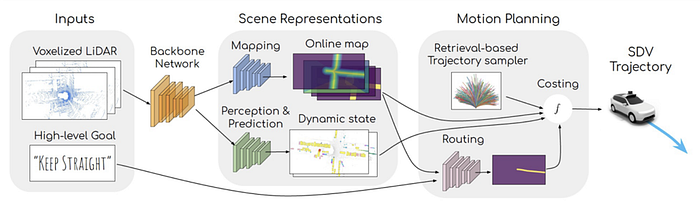
5 How about the planning work?
It is the first time Tesla introduced the planning module, since the ADAS (L2 Autonomous Driving) system builds planning and control (P&C) for each function, like ACC, LKA/LDW etc., but the FSD (full-self driving) system requires a pipeline of perception (as well as mapping & localization), prediction, planning and control in a stack.
Tesla’s planning methods mostly act like traditional methods, similar to Baidu Apollo’s EM planner or Lattice planner.
https://arxiv.org/pdf/1807.08048.pdf
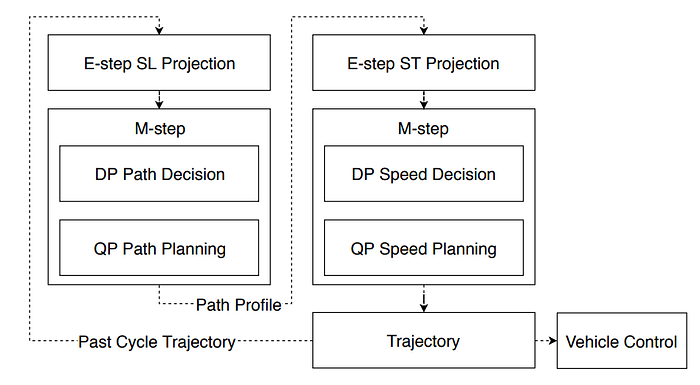
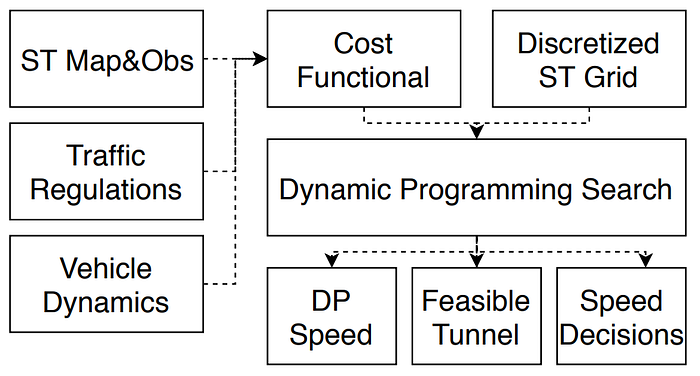
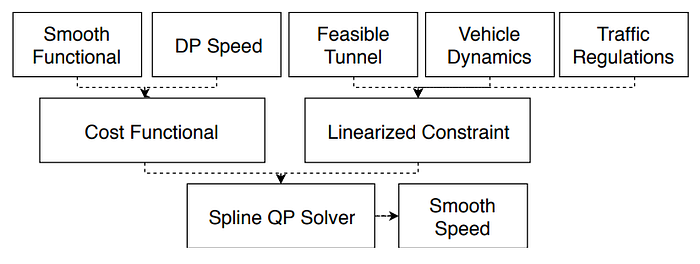
In famous DARPA (Defense Advanced Research Projects Agency)’s Grand and Urban Challenge (2004–2007), CMU’s AD platform named as “BOSS”, has proposed the hierarchical planning system, i.e. mission planning (route), behavior planning (decision making) and motion planning (trajectory) etc. Apparently Tesla’s work refers to behavior planning and motion planning.
Note: The traditional GPS navigation tool runs route planning only (routing), without assistance of lane-based map info. Sometimes, part of rough mission planning is considered as well, like left or right turn, entry or exit of highways.
https://www.ri.cmu.edu/pub_files/2009/6/aimag2009_urmson.pdf

Let’s see Tesla’s planning strategy: it is a hierachical planning solution.


Note: traditional planning methods, different from data driven machine learning planning methods, usually are limited by scenario catogrization, for example, Baidu Apollo’s Lattice planner works suitable for closed highways, meanwhile Apollo EM planner for urban streets. Even the open planner exists suitable for unstructed road or the parking planner for the parking lot.
Tesla’s Hierarchical Planning demo for a left turn navigation
Though software director Ashok explained they had implemented joint planning, i.e. running Autopilot for each surrounding vehicle, it could be regarded as prediction. However, apparently interaction modeling is NOT mentioned, which is critical for prediction and behavior planning or decision making.

Note: What is Tesla’s prediction model for pedestrians or cyclists, physical model-based only or NN-based? It should be different from the one for vehicles.
Besides, Tesla has started working on the machine learning-based planning method for complex scenarios, which is borrowed from AlphaZero or MuZero: model-based Reinforcement Learning(RL) with Monte Carlo Tree-based Search (MCTS).
https://arxiv.org/pdf/1911.08265.pdf

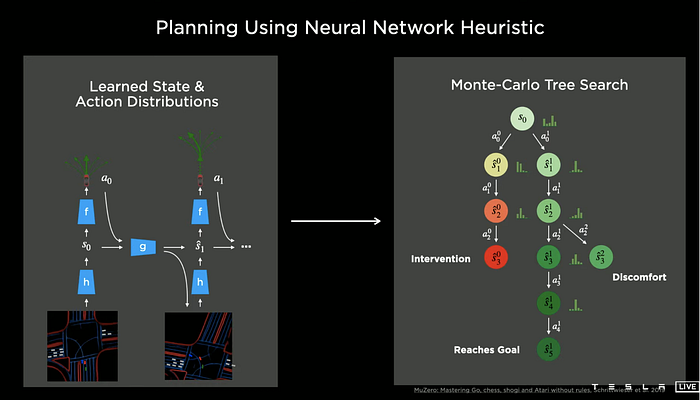
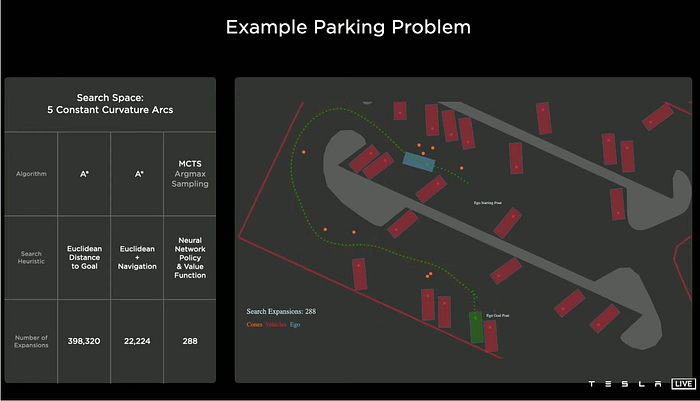
However, experiment demos on simulations of the parking problem, we doubt Tesla has released this advanced version to vehicles.
Let’s see what Google Waymo and Uber ATG has done in prediction and planning:
Google Waymo’s prediciton models, i.e. Multipath and TNT
https://arxiv.org/pdf/1910.05449.pdf
https://arxiv.org/pdf/2008.08294.pdf
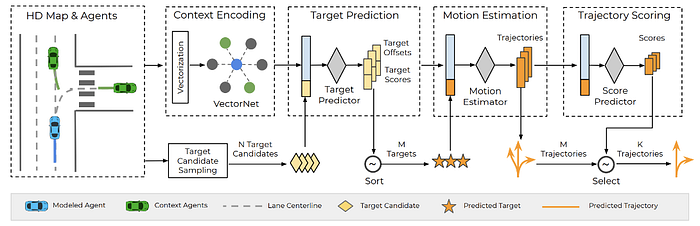
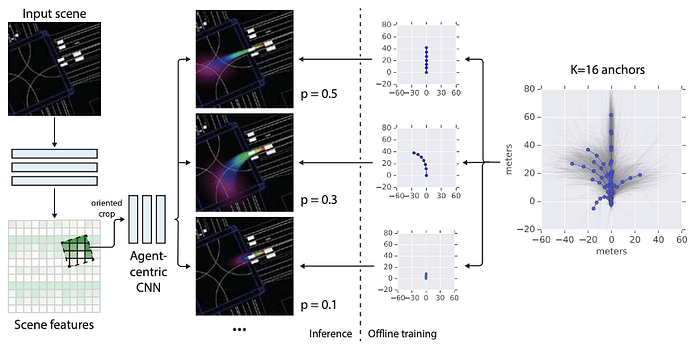
Uber R&D Perception, Localization & Prediction, i.e. LP2
https://arxiv.org/pdf/2101.06720.pdf
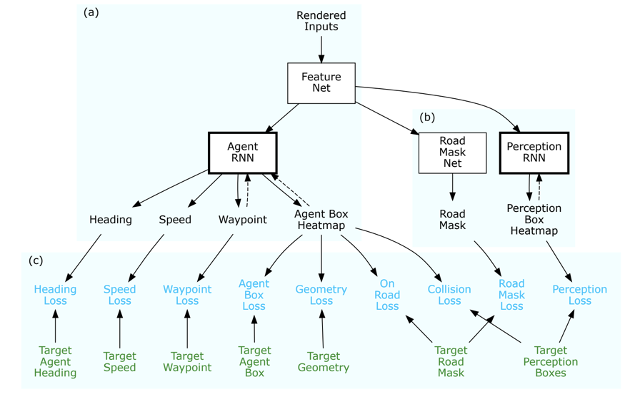
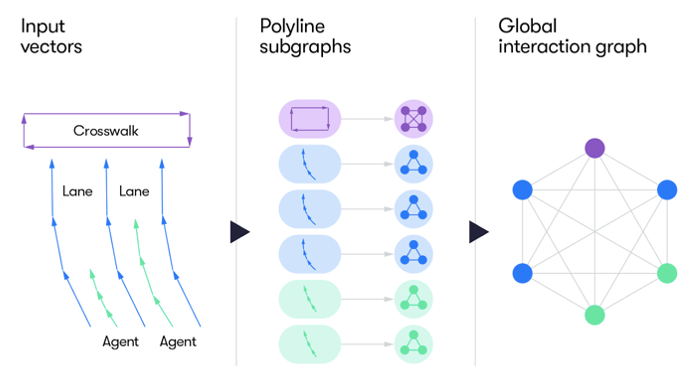
Google Waymo’s planning models, i.e. ChauffeurNet & VectorNet
https://arxiv.org/pdf/1812.03079.pdf
https://blog.waymo.com/2020/05/vectornet.html
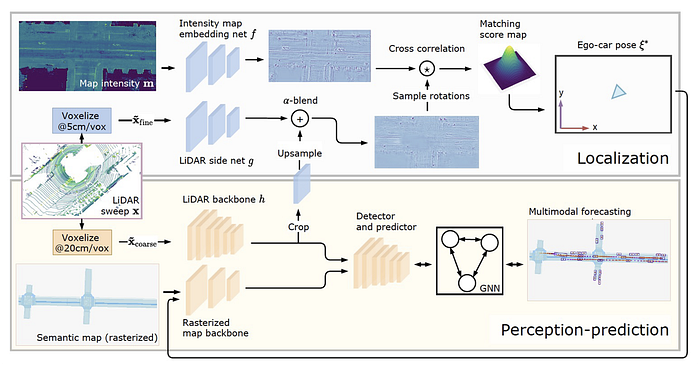
Uber R&D Perception, Prediction, Mapping & Planning, i.e. MP3
https://arxiv.org/abs/2101.06806
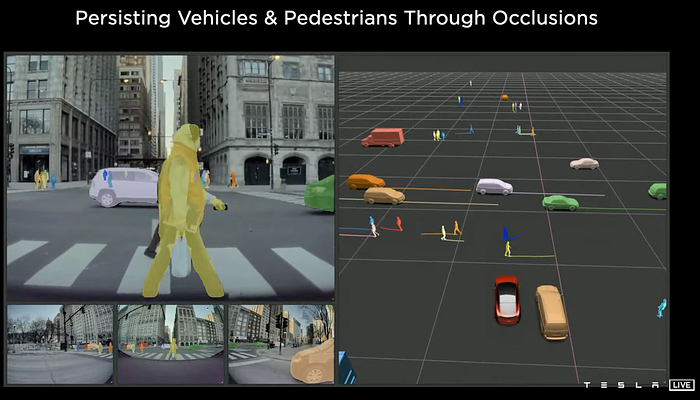
6 How about the auto-labeling tools?
Apparently the auto-labeling NN models can be regarded as teacher, while the on-vehicle inference models as student. The teacher models can run at the server offline, providing the guide for the student models, like knowledge distillation for model compression.
Note: We could speculate that the offline network architectures still tailor Transformer and RNN.
Meanwhile, the auto labeling tools provide 3-D scene reconstruction for mobile and static objects, kind of visual SLAM or visual-inertial SLAM. It could be implemented by deep NN as well, like Mobileye ViDAR (online).


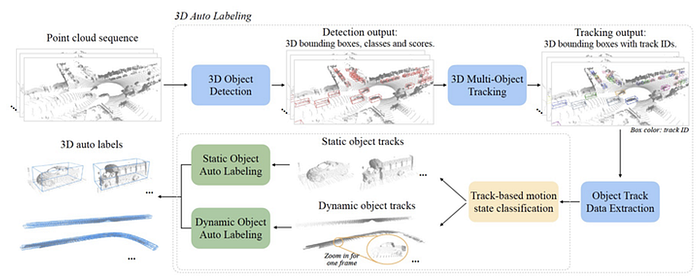
Interestingly, Google Waymo has implemented auto-labeling from LiDAR, published at CVPR’21:
https://arxiv.org/abs/2103.05073
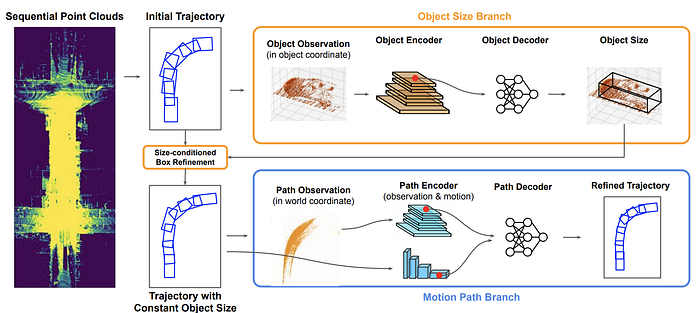
Uber developed as well a LiDAR-based autolabeling tool called Auto4D:
https://arxiv.org/abs/2101.06586
7 How about the simulation platform?
In Tesla Autonomy day in April 2019, Elon Mask once scoffed at Waymo’s simulation mileage, commenting that it acts like quiz by itself. However, some tailed events seldom occur in real scenes, like dogs in the highway or weird clothings at Halloween.

In Ashok’s presentation, the scene database is built, from hand made, procedural, to adversairal by ML (GAN-based?).

Actually the scenario dataset is applied for simulation test in autonomous driving industry, for example the well known PEGASUS (Project for the Establishment of Generally Accepted quality criteria, tools and methods as well as Scenarios and Situations for the release of highly-automated driving functions) project at Germany.
https://www.pegasusprojekt.de/en/about-pegasus


Let’s see what Google Waymo, Nvidia and Uber ATG do in simulation:
Google WayMo Simulation, i.e. SurfelGAN and Simulation City
https://arxiv.org/abs/2005.03844
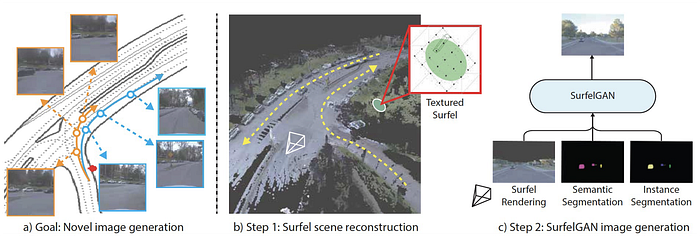

Nvidia Simulation, i.e. Drive Constellation and Drive Sim

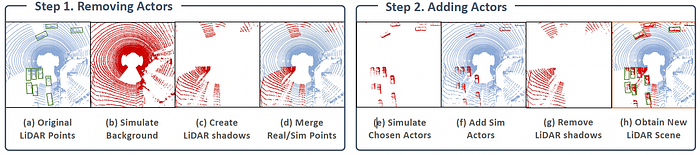
Uber ATG’s Simulation, i.e. GeoSim and AdvSim
https://arxiv.org/abs/2101.06543
https://arxiv.org/abs/2101.06549



8 What is Neural Rendering in simulation?
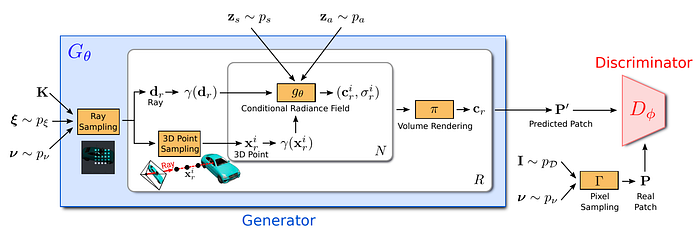
Neural Rendering is applied by Tesla for digital twin, i.e. recreating (real-to-virtual) a synthetic world with the same structure or semantics. It is not realized by ray tracing, the traditional rendering engine.

Demo of Neural Rendering for Scene Reproduction at Telsa
A survey of Neural Rendering is published at arXiv
https://arxiv.org/abs/2004.03805
“Neural rendering is a new and rapidly emerging field that combines generative machine learning techniques with physical knowledge from computer graphics, e.g., by the integration of differentiable rendering into network training.”
The best paper honorable mention at ECCV’2020 “Representing Scenes as Neural Radiance Fields for View Synthesis” from UC Berkeley and Google

And the published paper at NeuIPS’2020 “GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis”
The latest best paper at CVPR’21 “GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Field”
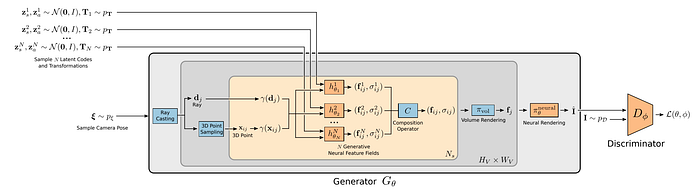
Let’s see what Neural Rendering is reported by Nvidia’s AI lab at Toronto U., Canada:
https://arxiv.org/abs/2010.09125
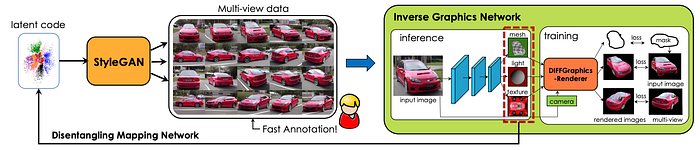
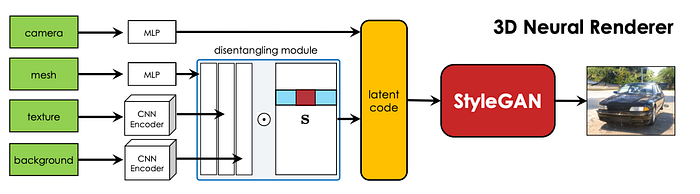
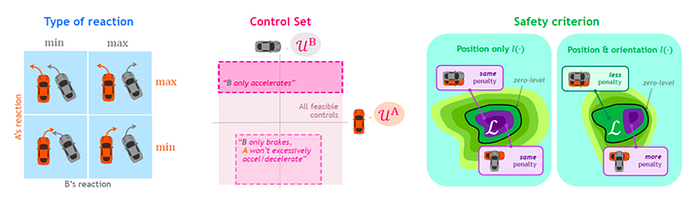
9 What is the safety model?
Safety is a big issue for self driving. However Tesla seems not addressing any issues on safety. For example, while collecting informative data by the triggers (more than 200), whether the FSD system could provide corner case detections or OOD (out-of-distribution) detections for failure prediction of Autopilot?
In SOTIF (Safety Of The Intended Function) standard, the difficult scenarios are “unknown unsafe” cases, the black swans. Therefore, it recommends the continuous improvement of autonomous drivers to maximize the portion of known safe scenarios.
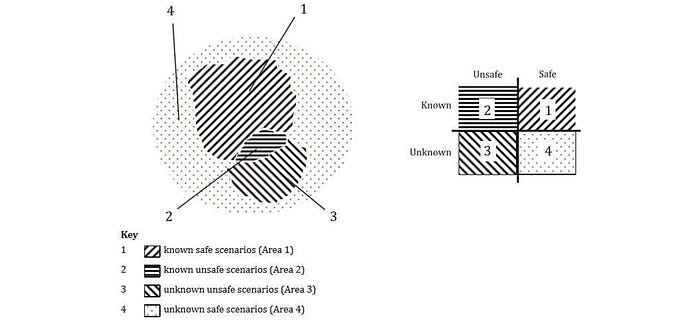
Uncertainty estimation is the technique to analysis the ML algorithm’s confidence, i.e. epistemic (model) uncertainty, and data intepretation, i.e. aleatoric (data) uncertainty. A survey paper for uncertainty-based object detection in autonomous driving is published at arXiv:
https://arxiv.org/abs/2011.10671


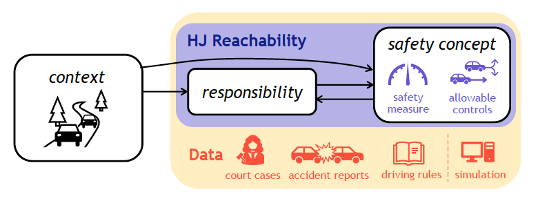
Mobileye’s RSS (Responsibility-Sensitive Safety) model and Nvidia’s SFF (Safety Force Field), try to explain safety in general theory at the obstacle avoidance level, kind of interpretable, mathematical modeling for safety assurance, like a white-box. Recently Nvidia researchers tried to unify the safety concepts in a HJ (Hamilton Jacobi) reachability framework:
https://arxiv.org/abs/2107.14412
10 Is there catastrophic forgetting?
A question about continuous learning was put forward at the Tesla AI day, however AK answered that there is no concern for it. Actually the problem for continuous learning or incremental learning is catastrophic forgetting, a dilemma of stability-plasticity. Obviously retraining from scratch is a naive solution.
A good survey about continuous learning is published:
https://arxiv.org/abs/1802.07569
Typical incremental learning methods are:
- Retraining while regularizing to prevent catastrophic forgetting with previously learned tasks
- Unchanged parameters with network extension for representing new tasks
- Selective retraining with possible expansion.

The main reasons causing the problem of catestrophic forgetting are:
- Weight drift
- Activation drift
- Inter-task confusion
- Task-recency bias
Closely related domains in machine learning include:
- Multi Task Learning
- Transfer Learning
- Domain Adaptation(part of Transfer Learning)
- Learning to Learn (Meta Learning)
- Online Learning (i.i.d data)
- Open World Learning(subset of continual learning)
11 What if the radar gets improved?
Tesla has removed radar from Autopilot since 2021. AK presented the advantages for the pure vision system at CVPR’21 workshop.
https://www.youtube.com/watch?v=NSDTZQdo6H8

Three demo examples were presented to explain:
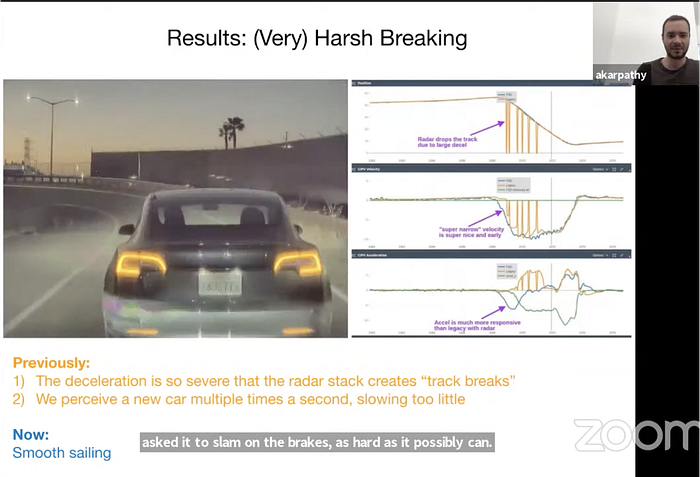

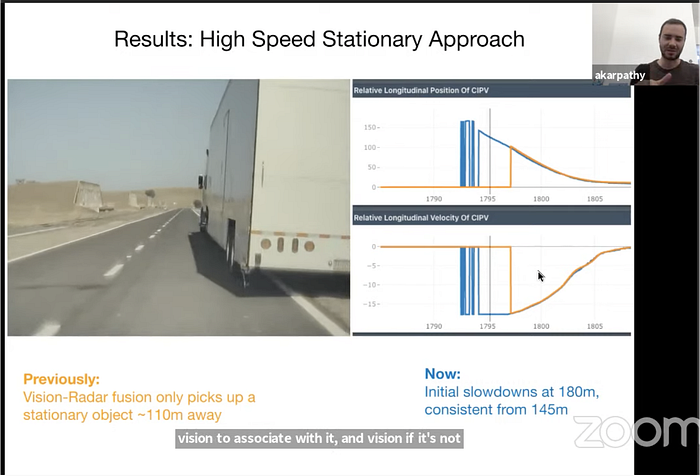
However in CES 2021 keynote speech, Mobileye CEO Amnon Shashua still insisted the three-way redundancy, camera-radar-liDAR, where radar and lidar can each function as standalone systems like cameras. But he said “radar today doesn’t have the resolution or the dynamic range.”
https://www.youtube.com/watch?v=B7YNj66GxRA

The problem of radar-camera fusion lies in the low resolution of radar signal for object detection. Amnon thinks radars need to evolve to “imaging radar”.
Current radars have 192 virtual channels thanks to 12 by 16 transmitters and receivers. It is not enough. The solution is “software-defined imaging radar”:
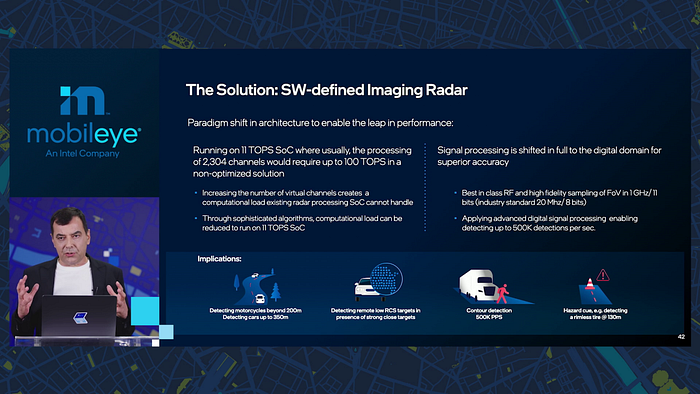
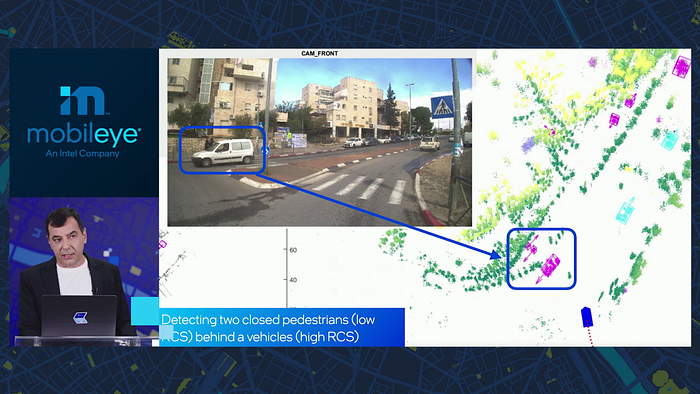
As I mentioned in sensor fusion, raw radar data could be directly converted to feature maps, rather than sparse object point cloud after echo processing and clustering.
12 What if the LiDAR gets improved?
LiDAR was criticized by Elon Mask in 2019. Based on “the first principal” assumption, he thinks machine learning can help Autopilot drive with cameras only, like humans.
We have to say, LiDAR cannot solve all challenging problems which happen in the camera system, for example, bad weather conditions as fog, snow and rain. Besides, LiDAR is expensive, more than radar too. Furthermore, the ranging distance is also an open issue for concern.
As a matter of fact, LiDAR-based algorithms developed by researchers don’t use complete raw point cloud/reflectivity data. The object detection methods based on LiDAR point cloud are classified as three caegories: projection to images, 3-d regular grid to voxels of a volume and feature maps encoded by combination of max pooling and multi-layer perceptron (MLP).

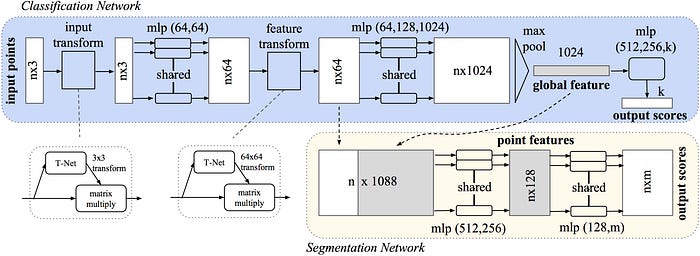
LiDAR are classified as mechanic, MEMS and solid state. It is expected solid state LiDAR can be mature, valid for reducing device cost and satisfying vehicle regulations. However, Amnon commented the current LiDAR’s sensing is based on ToF (time of flight), instead FMCW (frequency-modulation coherent wave) is “the next frontier”, which is also 4-D, able to capture the velocity of objects, with longer range and being more resilent. “Game change”, as he said.


